YoloV4 自建数据集训练过程
需求是完成对于锥桶的识别的任务
1.yolov4环境搭建
下载darknet
在Ubuntu终端下克隆该工程
git clone https://github.com/AlexeyAB/darknet.git
编译darknet
在编译前,首先需要修改Makefile,在终端输入以下命令:
cd darknet
gedit Makefile
如果仅在cpu下尝试,则不进行改动
如在gpu下运行,则需要修改GPU CUDNN OPENCV的参数
需要安装opencv,采用以下命令
sudo apt-get install libopencv-dev
MakeFile中的两个关键点:
1.选择ARCH.根据平台的不同,将支持平台 赋值给ARCH参数
2.设置NVCC的实际路径 一般为: /usr/local/cuda-10.1/bin/nvcc
设置完毕后,编译:
make或者多核可采用make -j8
测试
编译完成后,下载权重文件进行测试
https://drive.google.com/open?id=1cewMfusmPjYWbrnuJRuKhPMwRe_b9PaT
完成权重下载后,可以编写shell版本
test_yolo.sh的内容:
./darknet detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights -thresh 0.25 data/dog.jpg
熟悉的结果
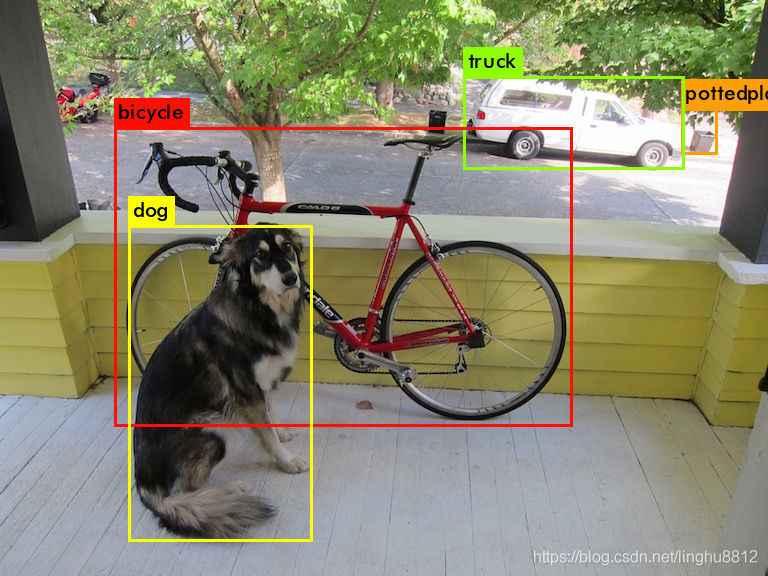
说明环境配置成功
2.图片标注
在线标注工具 makesense
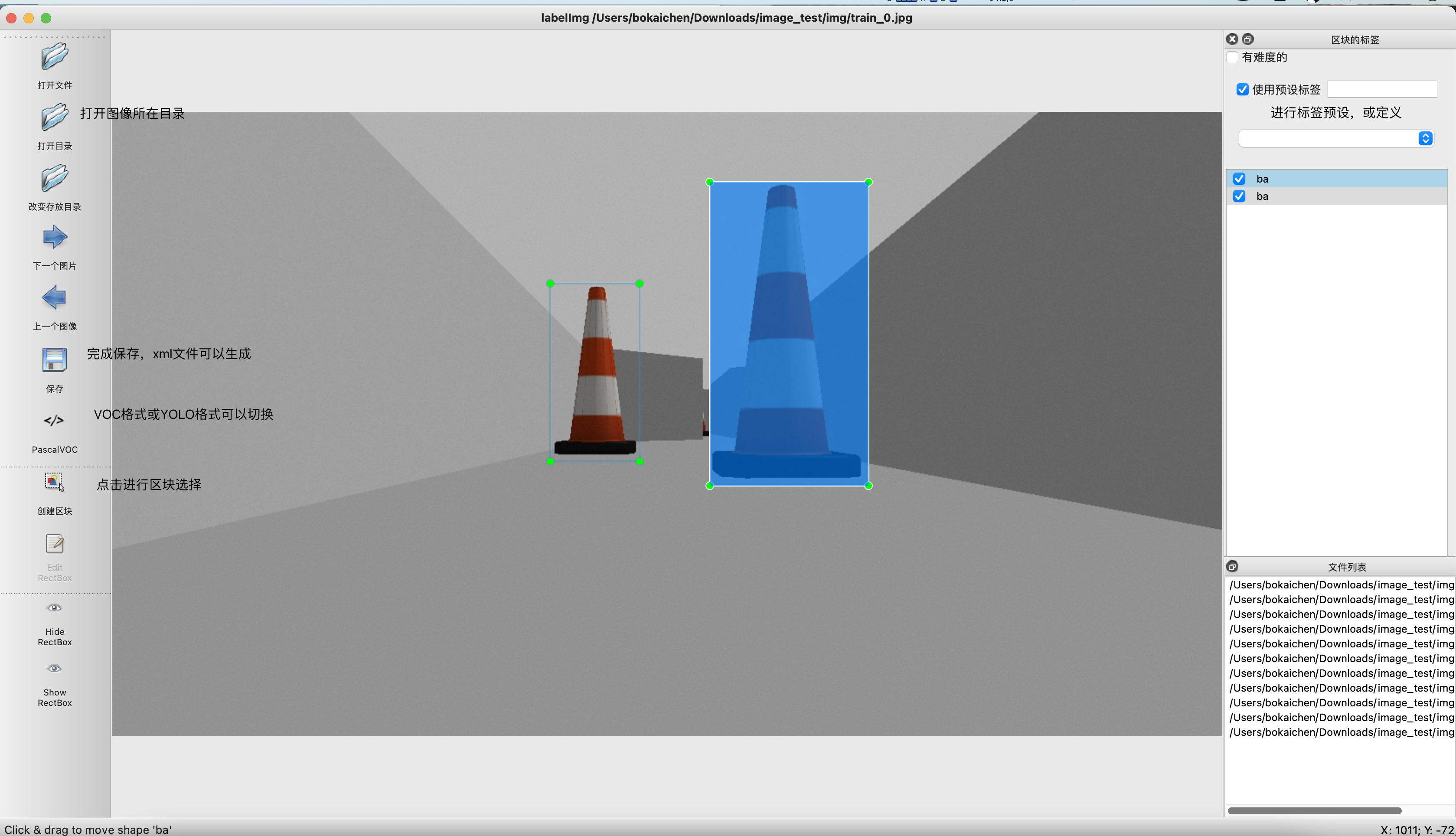
本地标注功能 LabelImg
标注后会产生对应名字的xml文件
Label是目标检测数据标注工具,可以标注两种格式:
- VOC标签格式,标注的标签存储在xml文件
- YOLO标签格式,标注的标签存储在txt文件中
pip install labelimg
Python3环境使用命令安装
sudo apt-get install pyqt5-dev-tools
sudo pip3 install -r requirements/requirements-linux-python3.txt
make qt5py3
python3 labelImg.py
python3 labelImg.py [IMAGE_PATH] [PRE-DEFINED CLASS FILE]
LabelImg的使用
命令labelimg打开
3.VOC数据集处理
经过标定后,形成了图片和xml组成的文件夹
利用上述文件,组成VOC的数据集格式
利用yolov4训练 需要将文件组织成yolo的数据集形式(txt)
所以涉及两个工作
- 进行VOC数据集格式的生成
- 将其转化为yolo格式
- 创建VOC目录
#make_voc_dir.py
import os
os.makedirs("VOCdevkit/VOC2007/Annotations")
os.makedirs("VOCdevkit/VOC2007/JPEGImages")
os.makedirs("VOCdevkit/VOC2007/ImageSets/Main/")
将标签放入Annotations,图片放入JPEGImages
- 生成xml对应的txt文件,执行split_data.py
# split_data.py 将JPEGImages下的所有文件分成训练集,测试集,生成ImageSets下Main文件夹中的txt文件。
import os
import random
xmlfilepath=r'/home/dlm/yolov4_split_shujuji/VOCdevkit_person/VOC2007/Annotations' #自己数据集中xml的路径
saveBasePath=r"/home/dlm/yolov4_split_shujuji/VOCdevkit_person/" # 保存路径
trainval_percent=0.9 #训练集和验证集的比例调整
train_percent=0.9
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'/home/dlm/yolov4_split_shujuji/VOCdevkit_person/VOC2007/ImageSets/Main/trainval.txt'), 'w') # txt文件储存的路径
ftest = open(os.path.join(saveBasePath,'/home/dlm/yolov4_split_shujuji/VOCdevkit_person/VOC2007/ImageSets/Main/test.txt'), 'w') #
ftrain = open(os.path.join(saveBasePath,'/home/dlm/yolov4_split_shujuji/VOCdevkit_person/VOC2007/ImageSets/Main/train.txt'), 'w') #
fval = open(os.path.join(saveBasePath,'/home/dlm/yolov4_split_shujuji/VOCdevkit_person/VOC2007/ImageSets/Main/val.txt'), 'w') #
for i in list:
#name="/home/dlm/yolov4_split_shujuji/VOCdevkit_person/VOC2007/JPEGImages/" + total_xml[i][:-4]+ '.jpg' + '\n'
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
执行完之后会在main文件夹下生成完整版共4个txt文件,分别为:trainval.txt, train.txt, val.txt, test.txt。注意:这些文件中的图片名称必须是不包含路径以及后缀.jpg或者.png.
- 执行voc_label
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["car"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2007_train.txt 2007_val.txt > train.txt")
os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt > train.all.txt")
执行完voc_label.py后生成的trainval.txt, train.txt, val.txt, test.txt拷贝到mian文件夹下替换掉里面没路径的trainval.txt, train.txt, val.txt, test.txt这四个txt文件。
classes的配置和sets需要根据情况而定
此时生成的txt文件中必须是
/home/dlm/yolov4_split_shujuji/VOCdevkit_person/VOC2007/JPEGImages/8.jpg)
全路径,完整的路径.
至此,yolo的数据集格式已经建立完毕.
4.yolov4训练过程配置
需要修改的配置参数有三处:
- data文件夹下的
.names文件. - cfg文件夹下的
.data文件 - cfg文件夹下的
.cfg文件
.names文件描述了模型需要训练的数据类别,一行一个类,每个类独立成行
.data描述了train.txt和val.txt的绝对路径,参数名字为train和valid,而不是train和val
classes= 1
train = /home/jys/darknet-yolov4/2007_train.txt
valid = /home/jys/darknet-yolov4/2007_val.txt
names = data/ba.names
backup = /home/jys/darknet-yolov4/backup
eval=coco
.cfg描述了训练参数,需要修改的主要有:
-
修改batch=64,修改subdivisions=64(如果显卡性能高可以设置batch=96,sudivisions=16;) batch的含义为一次喂给网络多少张图片 subdivisions的含义为将batch数量的图片分成多少份喂入
-
修改width的尺寸(416或608)
-
修改max_batches=classes*2000,max_batches表示最终的迭代次数.
-
修改classes,搜索[yolo]可以找到关键字位置
-
修改filters,filters=(classes + 5)*3,搜索[yolo]可以找到convolutional中的filters关键字位置
-
下载预训练权重,放入darknet主目录下 权重下载地址:
https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.conv.137
- 用该命令进行训练
./darknet detector train cfg/ba.data cfg/yolov4-voc-ba.cfg yolov4.conv.137 #(每1000轮保存一个权重)
- 如果需要中途停止后,继续训练
./darknet detector train cfg/person.data cfg/yolov4-person.cfg backup/yolov4_2000.weights
5.训练及结果
训练跑起来后 会显示对应的loss和epoch图
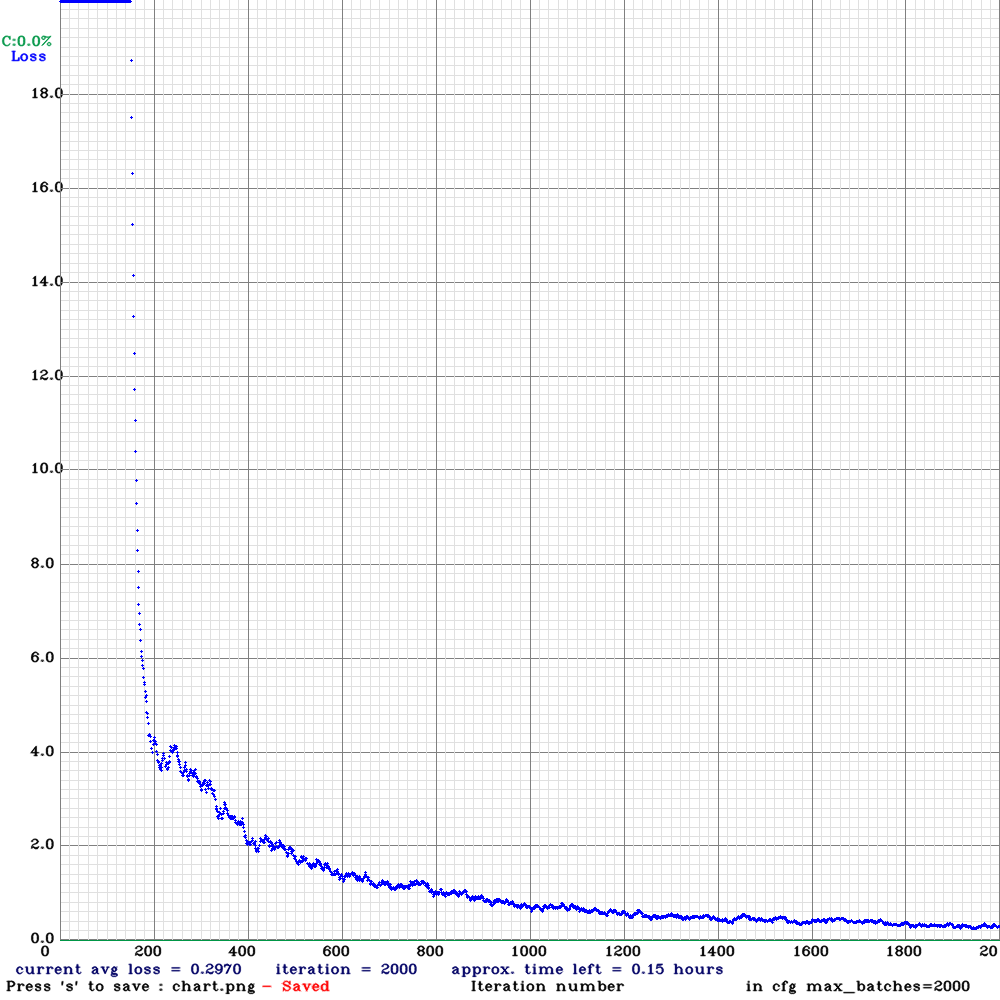
等待完全结束后,可以进行detect的测试,也可以利用backup文件中的临时权重文件测试其效果
效果还是可以的

效果拔群 撒花✿✿ヽ(°▽°)ノ✿