jetson-inference 实践中的问题
实践pytorch、TensorRT技术栈
利用项目jetson-inference学习
项目地址:https://github.com/dusty-nv/jetson-inference.git
安装中的问题
1.recursive 没有安装git子模块
利用git clone --recursive命令更新子模块
完成utils等模块的克隆
2.cmake的问题
cmake时遇到not detect python3.7的问题
安装后,numpy无法找到 ModuleNotFoundError: No module named 'numpy'
没有找到python3.7的aarch64版本 提交issue,作者回答是python3.7不是必须安装的
继而卸载python3.7,往前倒发现问题是没有安装Doxygen
Doxygen介绍
Doxygen是一款文档生成工具,它可以从代码中提取出相应的文档,并组织,输出成各种漂亮的文档
安装命令
$ sudo apt-get update
$ sudo apt-get install git cmake libpython3-dev python3-numpy
$ git clone --recursive https://github.com/dusty-nv/jetson-inference
$ cd jetson-inference
$ mkdir build
$ cd build
$ cmake ../
$ make -j$(nproc)
$ sudo make install
$ sudo ldconfig
install时出现问题
无法找到python/jetson的文件夹
jetson-inference/python/bindings/../python/jetson
Makefile:117: recipe for target 'install' failed
是因为python/jetson无法找到 因为文件下目录时Jetson大写
生成一个jetson的文件夹 复制Jetson/的内容,执行sudo make install 通过
摄像头安装的问题
工程支持的摄像头有:MIPI-CSI-camera V4L2-camera RTP-stream
之前采用的摄像头属于V4L2-camera
但是利用camera输出是,无法得到图像.
作者提到了V4L2 Formats的问题
By default, V4L2 cameras will be created using the camera format with the highest framerate that most closely matches the desired resolution (by default, that resolution is 1280x720). The format with the highest framerate may be encoded (for example with H.264 or MJPEG), as USB cameras typically transmit uncompressed YUV/RGB at lower framerates. In this case, that codec will be detected and the camera stream will automatically be decoded using the Jetson's hardware decoder to attain the highest framerate.
If you explicitly want to choose the format used by the V4L2 camera, you can do so with the
--input-width,--input-height, and--input-codecoptions. Possible decoder codec options are--input-codec=h264, h265, vp8, vp9, mpeg2, mpeg4, mjpeg
但是此摄像头输出是YUY2 应该只是帧数低,并不会没有stream输出.随后更换罗技C270摄像头,问题解决.
查看v4l2摄像头参数
$ sudo apt-get install v4l-utils
$ v4l2-ctl --device=/dev/video0 --list-formats-ext
另外,MIPI CSI摄像头支持命令
$ video-viewer csi://0 # MIPI CSI camera 0 (substitue other camera numbers)
$ video-viewer csi://0 output.mp4 # save output stream to MP4 file (H.264 by default)
$ video-viewer csi://0 rtp://<remote-ip>:1234 # broadcast output stream over RTP to <remote-ip>
imagenet/detectnet/segnet都很顺利
训练数据中出现的问题
在安装pytorch时,在pypi网站无法找到对应版本,在NVIDIA完成版本,import时发送错误
无法引入cuda下的开发包 后来通过编辑/etc/profile,引入cuda的全局变量
export PATH=$PATH:/usr/local/cuda-10.0/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr.local/cuda-10.0/lib64
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda-10.0/lib64
而后出现cudann8.0无法导入
需要降级pytorch版本
在python的pypi站点没有找到支持aarch64版本的pytorch,从NVIDIA的一个链接找到了响应版本的下载地址
https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-7-0-now-available/72048
下载后安装,没问题
安装torch-vision时,也未能找到对应版本 而后在github的工程中
https://github.com/pytorch/vision下载了对应版本
pytorch1.5支持的是V0.6版本
然后利用cat_dog开始训练,训练完成后获得checkpoint.pth.rar和model_best.pth.tar两个文件
利用onnx_export.py将其转换为resnet18.onnx
然后利用imagenet进行识别测试
NET=models/cat_dog
DATASET=data/cat_dog
# C++
imagenet --model=$NET/resnet18.onnx --input_blob=input_0 --output_blob=output_0 --labels=$DATASET/labels.txt $DATASET/test/cat/01.jpg cat.jpg
出现的问题是 TensorRT无法导入
ERROR: ModelImporter.cpp:296 In function importModel:
搜索问题 Re-training on the Cat/Dog Dataset #370以为是vision的版本问题
回答中,作者写了自己安装的torchvision版本,安装后在后续答案中发现是pytorch版本过高导致的
安装指示安装了`torch1.2版本
安装地址是https://forums.developer.nvidia.com/t/pytorch-for-jetson-version-1-7-0-now-available/72048
好像除此之外没有找到...
重新完成训练,expert为onnx,在imagenet加载时,会将resnet18.onnx转换为resnet18.onnx.5106.GPU.FP16.engine
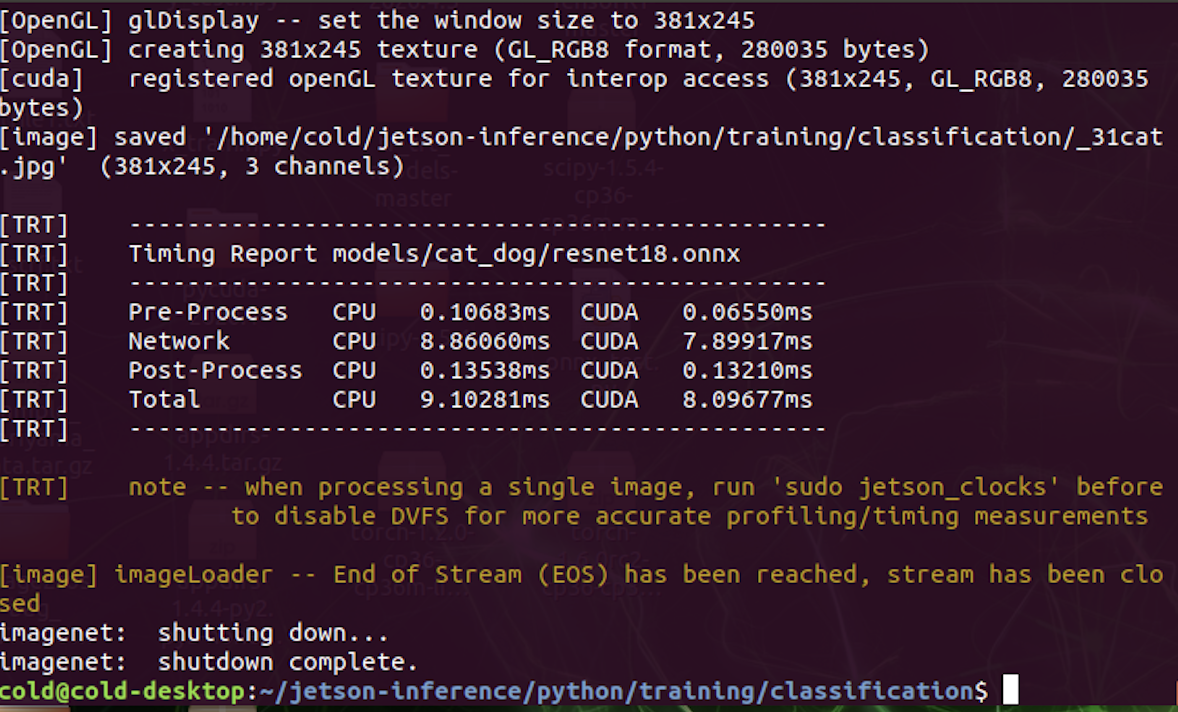
识别过程只有0.13210ms
整个图像识别30帧也不会掉帧.
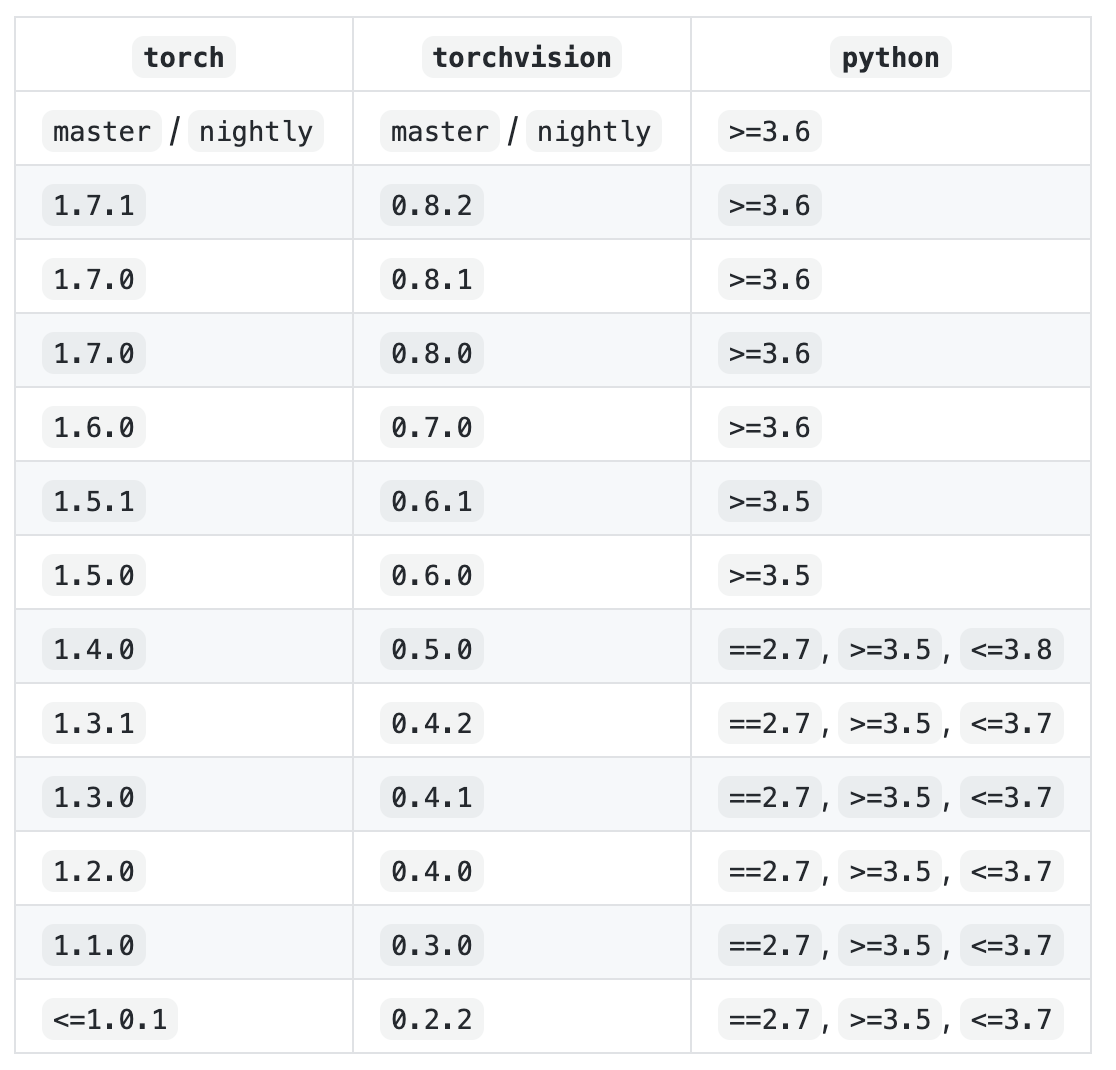
最后影响的主要问题来自于torch版本
贴一张版本的对应图
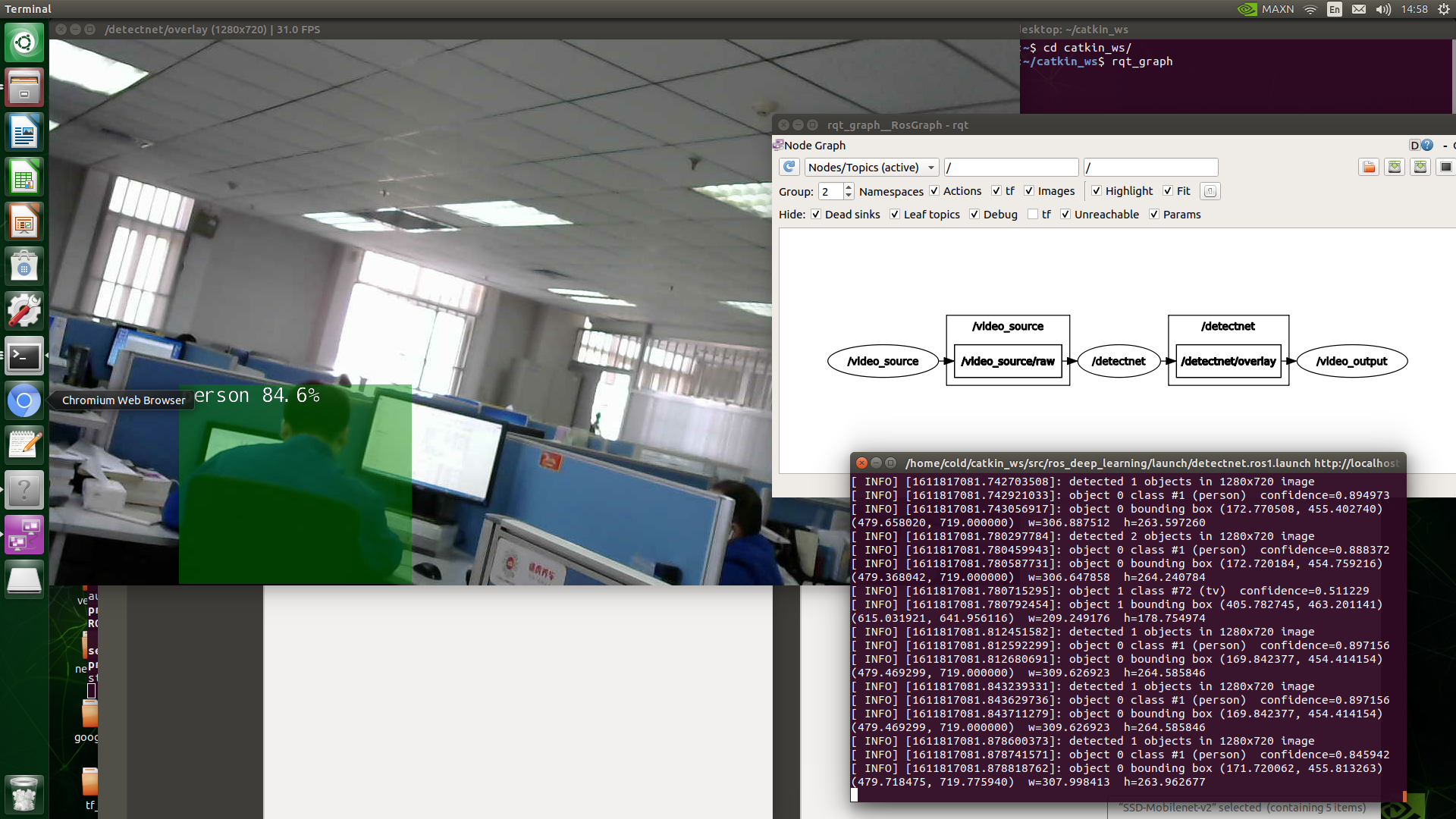
关于ros_deep_learning的搭载
安装
sudo apt-get install ros-melodic-image-transport ros-melodic-vision-msgs
关于创建工作空间之类的,太久不用就忘记了,记录一下
http://wiki.ros.org/ROS/Tutorials/InstallingandConfiguringROSEnvironment#Create_a_ROS_Workspace
$ cd ~/ros_workspace/src
$ git clone https://github.com/dusty-nv/ros_deep_learning
摄像头搭载:
- MIPI CSI camera : csi://0
- V4L2 camera : v4l2:///dev/video0
- RTP stream. : rtp://@1234
- Video file. : file://my_video.mp4
imagenet Node
# ROS Melodic
$ roslaunch ros_deep_learning imagenet.ros1.launch input:=csi://0 output:=display://0
detectent Node
# ROS Melodic
$ roslaunch ros_deep_learning detectnet.ros1.launch input:=csi://0 output:=display://0
segnet Node
# ROS Melodic
$ roslaunch ros_deep_learning segnet.ros1.launch input:=csi://0 output:=display://0
imagenet Node
| Topic Name | I/O | Message Type | Description |
|---|---|---|---|
| image_in | Input | sensor_msgs/Image |
Raw input image |
| classification | Output | vision_msgs/Classification2D |
Classification results (class ID + confidence) |
| vision_info | Output | vision_msgs/VisionInfo |
Vision metadata (class labels parameter list name) |
| overlay | Output | sensor_msgs/Image |
Input image overlayed with the classification results |
| Parameter Name | Type | Default | Description |
|---|---|---|---|
| model_name | string |
"googlenet" |
Built-in model name (see here for valid values) |
| model_path | string |
"" |
Path to custom caffe or ONNX model |
| prototxt_path | string |
"" |
Path to custom caffe prototxt file |
| input_blob | string |
"data" |
Name of DNN input layer |
| output_blob | string |
"prob" |
Name of DNN output layer |
| class_labels_path | string |
"" |
Path to custom class labels file |
| class_labels_HASH | vector |
class names | List of class labels, where HASH is model-specific (actual name of parameter is found via the vision_info topic) |
detectnet Node
| Topic Name | I/O | Message Type | Description |
|---|---|---|---|
| image_in | Input | sensor_msgs/Image |
Raw input image |
| detections | Output | vision_msgs/Detection2DArray |
Detection results (bounding boxes, class IDs, confidences) |
| vision_info | Output | vision_msgs/VisionInfo |
Vision metadata (class labels parameter list name) |
| overlay | Output | sensor_msgs/Image |
Input image overlayed with the detection results |
| Parameter Name | Type | Default | Description |
|---|---|---|---|
| model_name | string |
"ssd-mobilenet-v2" |
Built-in model name (see here for valid values) |
| model_path | string |
"" |
Path to custom caffe or ONNX model |
| prototxt_path | string |
"" |
Path to custom caffe prototxt file |
| input_blob | string |
"data" |
Name of DNN input layer |
| output_cvg | string |
"coverage" |
Name of DNN output layer (coverage/scores) |
| output_bbox | string |
"bboxes" |
Name of DNN output layer (bounding boxes) |
| class_labels_path | string |
"" |
Path to custom class labels file |
| class_labels_HASH | vector |
class names | List of class labels, where HASH is model-specific (actual name of parameter is found via the vision_info topic) |
| overlay_flags | string |
"box,labels,conf" |
Flags used to generate the overlay (some combination of none,box,labels,conf) |
| mean_pixel_value | float |
0.0 | Mean pixel subtraction value to be applied to input (normally 0) |
| threshold | float |
0.5 | Minimum confidence value for positive detections (0.0 - 1.0) |
segnet Node
| Topic Name | I/O | Message Type | Description |
|---|---|---|---|
| image_in | Input | sensor_msgs/Image |
Raw input image |
| vision_info | Output | vision_msgs/VisionInfo |
Vision metadata (class labels parameter list name) |
| overlay | Output | sensor_msgs/Image |
Input image overlayed with the classification results |
| color_mask | Output | sensor_msgs/Image |
Colorized segmentation class mask out |
| class_mask | Output | sensor_msgs/Image |
8-bit single-channel image where each pixel is a classID |
| Parameter Name | Type | Default | Description |
|---|---|---|---|
| model_name | string |
"fcn-resnet18-cityscapes-1024x512" |
Built-in model name (see here for valid values) |
| model_path | string |
"" |
Path to custom caffe or ONNX model |
| prototxt_path | string |
"" |
Path to custom caffe prototxt file |
| input_blob | string |
"data" |
Name of DNN input layer |
| output_blob | string |
"score_fr_21classes" |
Name of DNN output layer |
| class_colors_path | string |
"" |
Path to custom class colors file |
| class_labels_path | string |
"" |
Path to custom class labels file |
| class_labels_HASH | vector |
class names | List of class labels, where HASH is model-specific (actual name of parameter is found via the vision_info topic) |
| mask_filter | string |
"linear" |
Filtering to apply to color_mask topic (linear or point) |
| overlay_filter | string |
"linear" |
Filtering to apply to overlay topic (linear or point) |
| overlay_alpha | float |
180.0 |
Alpha blending value used by overlay topic (0.0 - 255.0) |
video_source Node
| Topic Name | I/O | Message Type | Description |
|---|---|---|---|
| raw | Output | sensor_msgs/Image |
Raw output image (BGR8) |
| Parameter | Type | Default | Description |
|---|---|---|---|
| resource | string |
"csi://0" |
Input stream URI (see here for valid protocols) |
| codec | string |
"" |
Manually specify codec for compressed streams (see here for valid values) |
| width | int |
0 | Manually specify desired width of stream (0 = stream default) |
| height | int |
0 | Manually specify desired height of stream (0 = stream default) |
| framerate | int |
0 | Manually specify desired framerate of stream (0 = stream default) |
| loop | int |
0 | For video files: 0 = don't loop, >0 = # of loops, -1 = loop forever |
video_output Node
| Topic Name | I/O | Message Type | Description |
|---|---|---|---|
| image_in | Input | sensor_msgs/Image |
Raw input image |
| Parameter | Type | Default | Description |
|---|---|---|---|
| resource | string |
"display://0" |
Output stream URI (see here for valid protocols) |
| codec | string |
"h264" |
Codec used for compressed streams (see here for valid values) |
| bitrate | int |
4000000 | Target VBR bitrate of encoded streams (in bits per second) |
最后贴一张效果图