Pytorch官方示例
Pytorch Tensor的通道排序:[batch,channel,height,width]
经卷积后的矩阵尺寸大小计算公式为:
N = ( W - F + 2P) / S + 1
- 输入图片的大小为 W x W
- Filter大小 F x F
- 步长 S
- padding的像素数 P
VGG
网络亮点: 通过堆叠多个3x3的卷积核来替代大尺度卷积核(减少所需参数)
论文中提到: 可以通过堆叠两个3x3的卷积核替代5x5的卷积核,堆叠三个3x3的卷积核替代7x7的卷积核
拥有相同的感受野
在卷积神经网络中,决定某一层输出结果中一个元素所对应的输入层的区域大小,被称为感受野(receptive field).通俗说,输出feature map上的一个单元对应输入层上的区域大小.
感受野计算公式:
F(i) = (F(i+1)-1) x Stride + Ksize
F(i)为第i层感受野
Stride为第i层的步距
Ksize为卷积核或池化核尺寸
文献中减去的RGB通道[123.68,116.78,103.94] 这是imagenet所有图形的RGB均值 如果基于迁移学习,需要减去这三个值(基于imagenet)
如果从头开始训练,则不需要减去
GoogleNet
网络亮点:
- 引入Inception结果(融合不同尺度的特征信息)
- 使用1x1的卷积核进行降维以及映射处理
- 添加两个辅助分类器帮助训练
- 丢弃全连接层,使用平均池化层(大大减少模型参数)
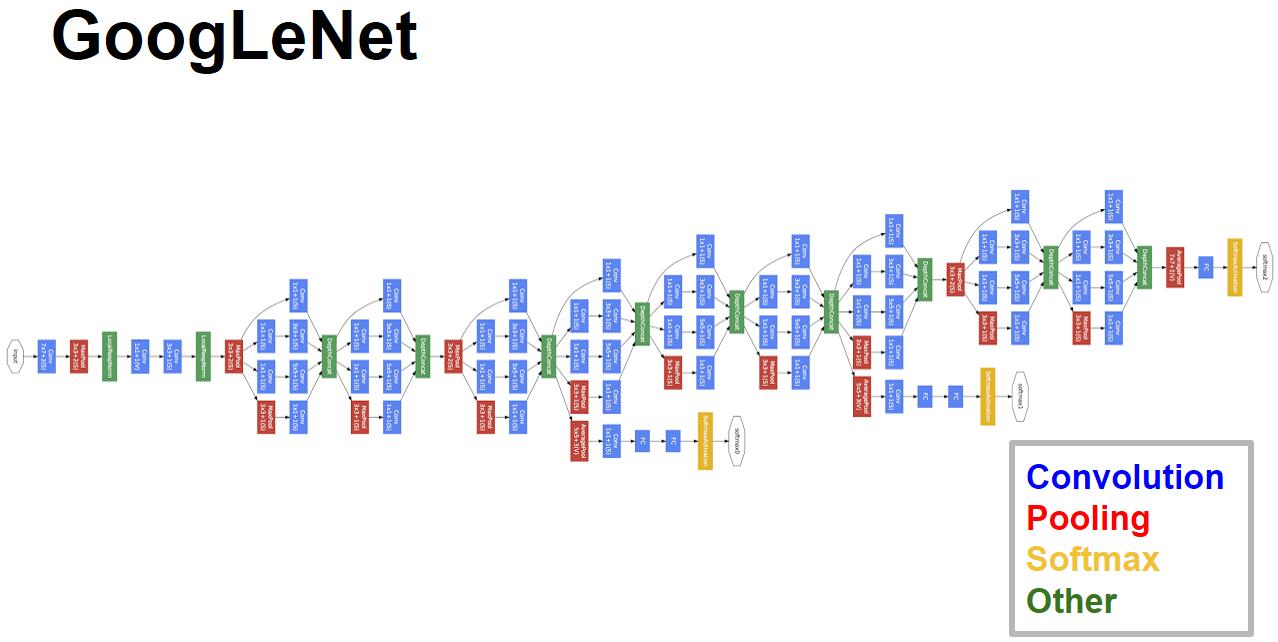
Inception结构
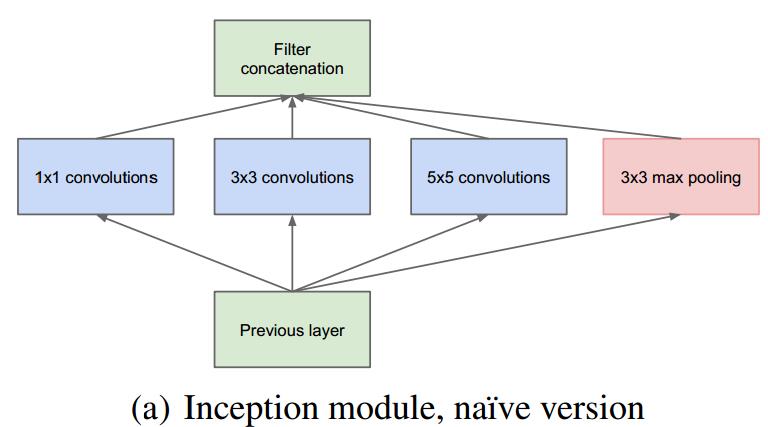
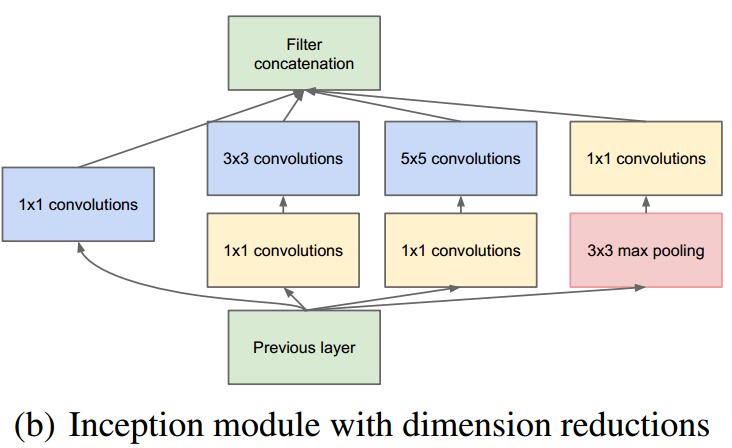
通过宽高相同的卷积结果进行纵向拼接
1x1卷积核
通过1x1的卷积核,使得channel数减少,从而减少训练参数
辅助分类器 Inception4A和Inception4D
辅助分类器,只在训练时起作用,推理时进行屏蔽 4x4x512 4x4x528
模型参数
GoogleNet模型参数是VGGNet的1/20
ResNet网络
网络中的亮点:
-
超深的网络结构(突破1000层)
梯度消失或梯度爆炸 (归一化 权重初始化 BN处理)
退化问题(degradation problem) (残差网络)
-
提出residual模块
实线残差结构的尺寸不改变,虚线残差结构需改变适应网络
Batch Nornalization的目的是调整feature map的分布为均值为0,方差为1的分布. BN层放在卷积层和激活层中间,不使用偏置bias.
迁移学习
能够快速的训练出一个理想的结果 当数据集较小时也能训练出理想的效果
注意:使用别人预训练模型参数时,要注意别人的预处理方式.
常见的迁移学习方式:
- 载入权重后训练所有参数
- 载入权重后只训练最后几层参数
- 载入权重后在原网络基础上再添加一层全连接层,仅训练最后一个全连接层
目标检测的指标评价
- coco
- pascal voc(之前用的比较多)
怎么才算正确检测到目标:
IOU大于指定阈值 类别正确 confidence大于指定阈值
目标检测中常见指标
TP(True Positive):loU>0.5的检测框数量(同一Ground Truth只计算一次) FP(False Positive):loU<=0.5的检测框(或者是检测到同一个GT的多余检测框的数量 FN(False Negative):没有检测到的GT的数量
Percision:TP/(TP + FP) 模型预测的所有目标中,预测正确的比例 (查准率) Recall: TP/(TP+FN) 所有真实目标中,模型预测正确的目标比例 (查全率)
AP:P-R 曲线下面积 P-R曲线:Precision-Recall曲线
mAP:mean Average Precision,即各类别AP的平均值
AlexNet
该网络的亮点在于:
- 首次利用进行网络加速训练
- 使用ReLU激活函数,而不是传统的Sigmoid激活函数以及Tanh激活函数
- 使用了LRN局部响应归一化
- 在全连接层的前两层中使用了Dropout随即失活神经元操作,以减少过拟合
从colab上将训练的模型下载下来:
from google.colab import files
files.download("AlexNet.pth")
pytorch中cpu和gpu load时相互转化torch.load
将gpu改为cpu时,遇到一个报错:
RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False. If you are running on a CPU-only machine, please use torch.load with map_location='cpu' to map your storages to the CPU.
此时改为:
torch.load("0.9472_0048.weights",map_location='cpu')
就可以解决问题
假设我们只保存了模型的参数(model.state_dict())到文件名为modelparameters.pth, model = Net()
1.cpu->cpu 或者gpu->gpu
checkpoint = torch.load('modelparameters.pth')
model.load_state_dict(checkpoint)
2.cpu->gpu 1
torch.load('modelparameters.pth', map_location=lambda storage, loc: storage.cuda(1))
3.gpu1 -> gpu0
torch.load('modelparameters.pth', map_location={'cuda:1':'cuda:0'})
- gpu->cpu
torch.load('modelparameters.pth', map_location=lambda storage, loc: storage)
pytorch torchvision transform
对PIL.Image进行变换
class torchvision.transforms.Compose(transforms)
将多个transform组合起来
transforms.Compose([
transforms.CenterCrop(10),
transforms.TnTensor(),
])
Transformer
Seq2seq model with "Self-attention"
self-Attention Layer 输入sequence 输出sequence
sequence can be parallelly computed.
use self-Attention Layer replace RNN in Anything
No position information in self-attention
MobileNet V3
更新Block
- 加入SE模块
- 更新了激活函数
- 减少卷积层的卷积核个数(32->16)
- 精简Last Stage
swish激活函数
swish x = x * σ(x)
h-swish[x] = x * ReLU6(x + 3)/6