TensorFlow之estimator详解
Estimator初识
框架结构
在介绍Estimator之前需要对它在TensorFlow这个大框架的定位有个大致的认识,如下图示:
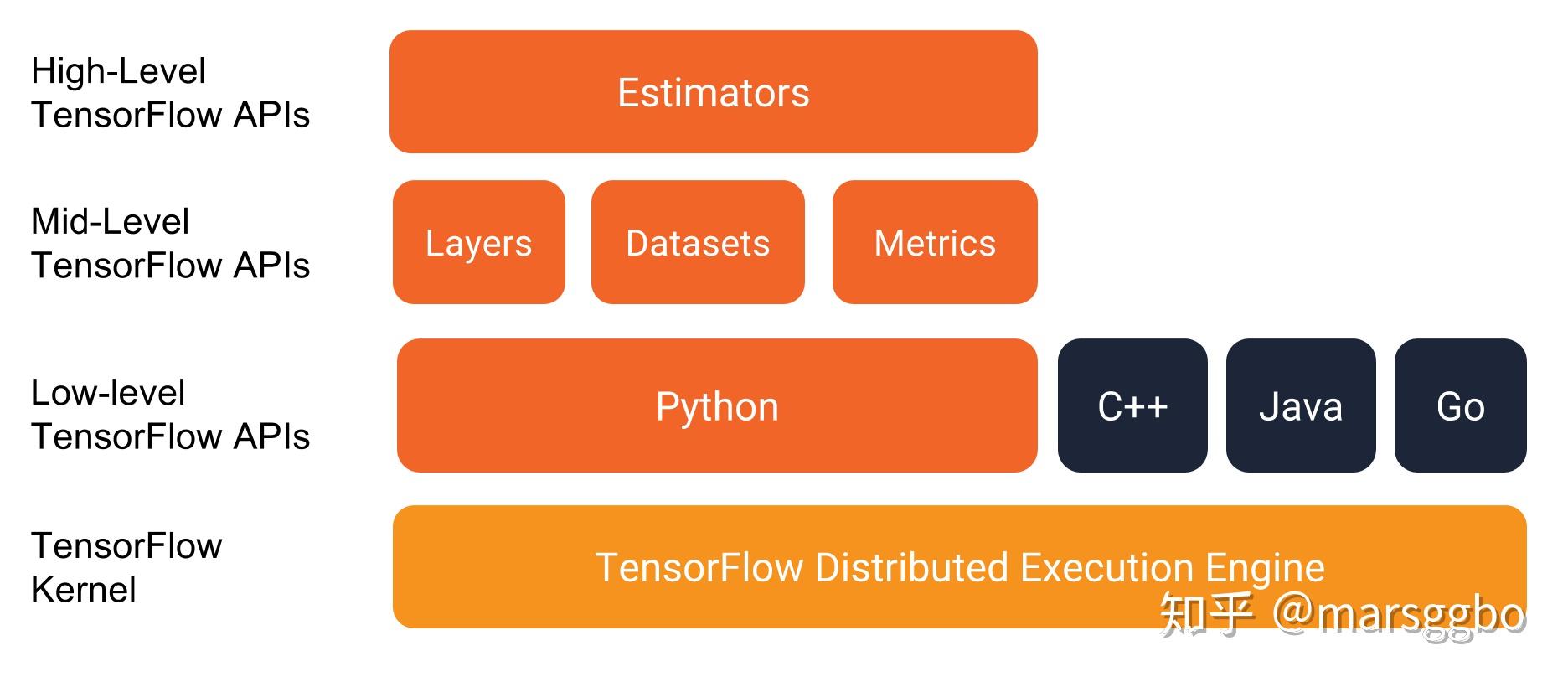
可以看到Estimator是属于High level的API,而Mid-level API分别是:
- Layers:用来构建网络结构
- Datasets: 用来构建数据读取pipeline
- Metrics:用来评估网络性能
可以看到如果使用Estimator,我们只需要关注这三个部分即可,而不用再关心一些太细节的东西,另外也不用再使用烦人的Session了。
Estimator使用步骤
- 创建一个或多个输入函数,即input_fn
- 定义模型的特征列,即feature_columns
- 实例化 Estimator,指定特征列和各种超参数。
- 在 Estimator 对象上调用一个或多个方法,传递适当的输入函数作为数据的来源。(train, evaluate, predict)
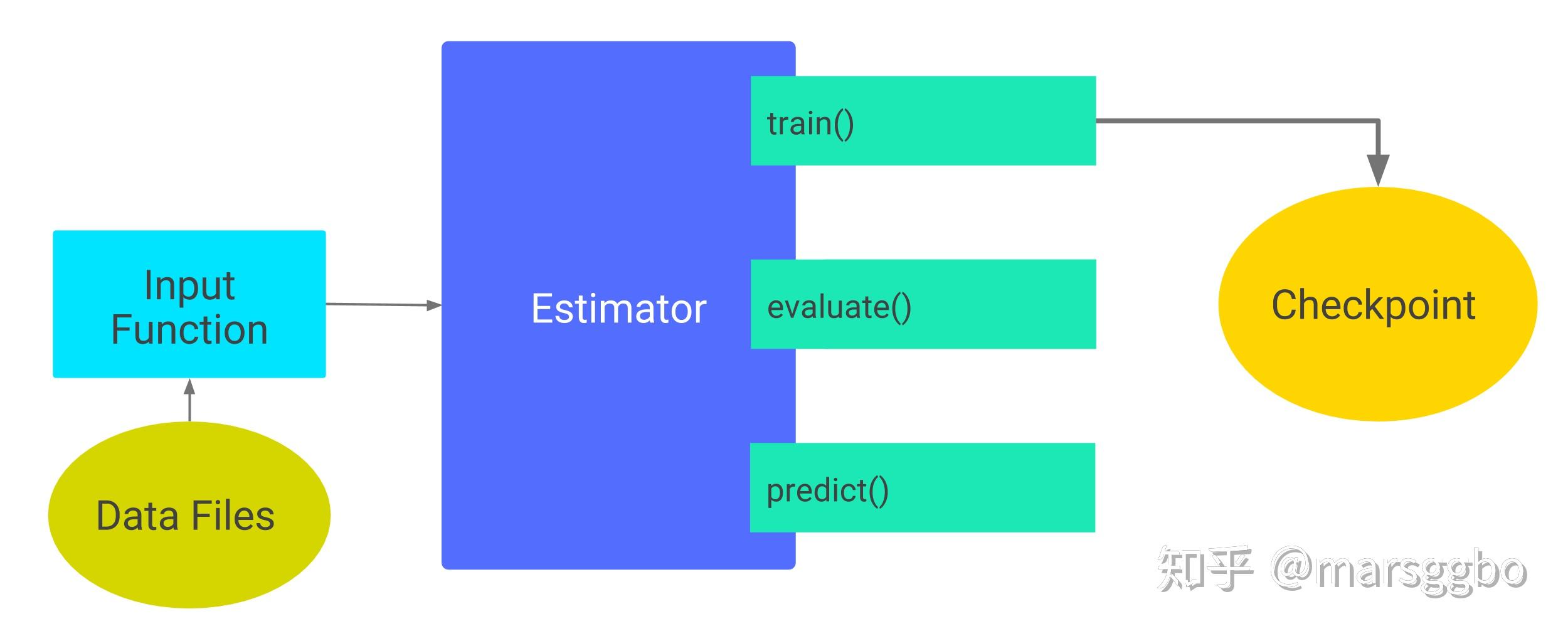
通过伪代码的形式介绍如何使用Estimator:
- 创建一个或多个输入函数,即input_fn:
def train_input_fn(features, labels, batch_size):
"""An input function for training"""
# Convert the inputs to a Dataset.
dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))
# Shuffle, repeat, and batch the examples.
return dataset.shuffle(1000).repeat().batch(batch_size)
features需要是字典 (另外此处的feature与我们常说的提取特征的feature还不太一样,也可以指原图数据(raw image),或者其他未作处理的数据)。下面定义的my_feature_column会传给Estimator用于解析features。
- 定义模型的特征列,即feature_columns
# Feature columns describe how to use the input.
my_feature_columns = []
for key in train_x.keys():
my_feature_columns.append(tf.feature_column.numeric_column(key=key))
- 实例化estimator,指定特征列和各种超参数
# Build a DNN with 2 hidden layers and 10 nodes in each hidden layer.
classifier = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,
# Two hidden layers of 10 nodes each.
hidden_units=[10, 10],
# The model must choose between 3 classes.
n_classes=3)
注意在实例化Estimator的时候不用把数据传进来,你只需要把feature_columns传进来即可,告诉Estimator需要解析哪些特征值,而数据集需要在训练和评估模型的时候才传。
- 在 Estimator 对象上调用一个或多个方法,传递适当的输入函数作为数据的来源
- train(训练)
#Train the Model.
classifier.train( input_fn=lambda:iris_data.train_input_fn(train_x, train_y, args.batch_size), steps=args.train_steps)
- evaluate(评估)
# Evaluate the model.
eval_result = classifier.evaluate( input_fn=lambda:iris_data.eval_input_fn(test_x, test_y, args.batch_size))
print('\nTest set accuracy: {accuracy:0.3f}\n'.format(**eval_result))
- predict(预测)
#Generate predictions from the model
expected = ['Setosa', 'Versicolor', 'Virginica']
predict_x = {
'SepalLength': [5.1, 5.9, 6.9],
'SepalWidth': [3.3, 3.0, 3.1],
'PetalLength': [1.7, 4.2, 5.4],
'PetalWidth': [0.5, 1.5, 2.1],
}
predictions = classifier.predict( input_fn=lambda:iris_data.eval_input_fn(predict_x,batch_size=args.batch_size))
深入理解Estimator
上面的示例中简单地介绍了Estimator,网络使用的是预创建好的DNNClassifier,其他预创建网络结构有如下:
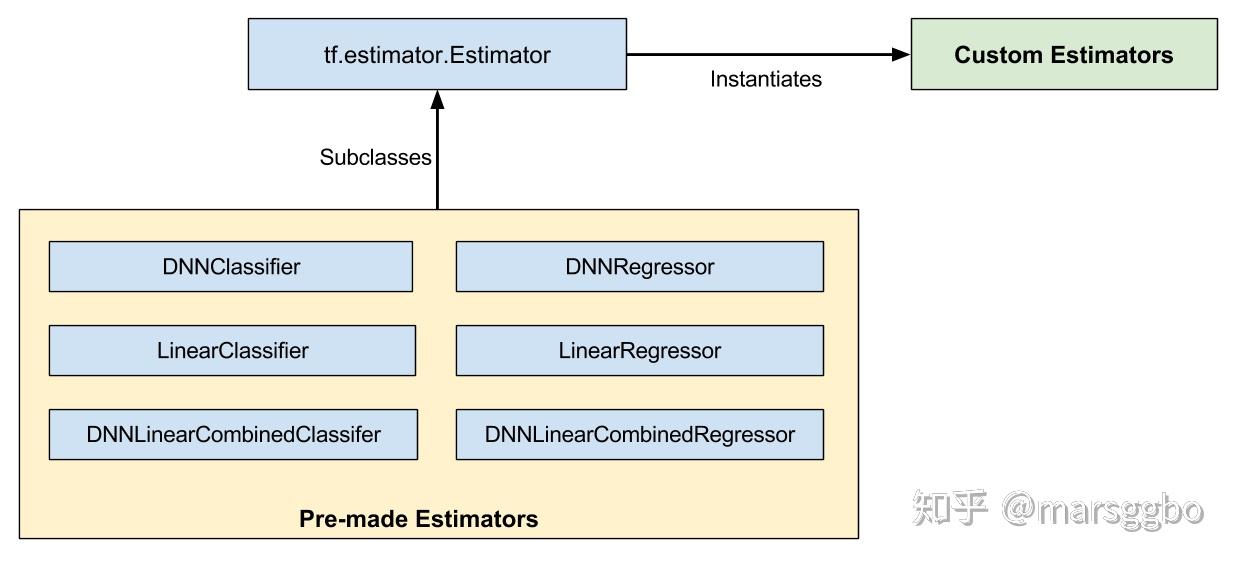
从源码理解Estimator
Estimator的源代码如下(为方便说明,已经掐头去尾):
class Estimator(object):
def __init__(self, model_fn, model_dir=None, config=None, params=None, warm_start_from=None):
...
可以看到需要传入的参数如下:
-
model_dir: 指定checkpoints和其他日志存放的路径。
-
model_fn: 这个是需要我们自定义的网络模型函数,后面详细介绍
-
config: 用于控制内部和checkpoints等,如果model_fn函数也定义config这个变量,则会将config传给model_fn
-
params: 该参数的值会传递给model_fn。
-
warm_start_from: 指定checkpoint路径,会导入该checkpoint开始训练
构建model_fn
模型函数一般定义如下:
def my_model_fn(
features, # This is batch_features from input_fn,`Tensor` or dict of `Tensor` (depends on data passed to `fit`).
labels, # This is batch_labels from input_fn
mode, # An instance of tf.estimator.ModeKeys
params, # Additional configuration
config=None
):
- 前两个参数是从输入函数中返回的特征和标签批次;也就是说,features 和 labels 是模型将使用的数据。
- params 是一个字典,它可以传入许多参数用来构建网络或者定义训练方式等。例如通过设置params['n_classes']来定义最终输出节点的个数等。
- config 通常用来控制checkpoint或者分布式什么,这里不深入研究。
- mode 参数表示调用程序是请求训练、评估还是预测,分别通过
tf.estimator.ModeKeys.TRAIN / EVAL / PREDICT来定义。另外通过观察DNNClassifier的源代码可以看到,mode这个参数并不用手动传入,因为Estimator会自动调整。例如当你调用estimator.train(...)的时候,mode则会被赋值tf.estimator.ModeKeys.TRAIN。
model_fn需要对于不同的模式提供不同的处理方式,并且都需要返回一个tf.estimator.EstimatorSpec的实例。
大白话版本就是:模型有训练,验证和测试三种阶段,而且对于不同模式,对数据有不同的处理方式。例如在训练阶段,我们需要将数据喂给模型,模型基于输入数据给出预测值,然后我们在通过预测值和真实值计算出loss,最后用loss更新网络参数,而在评估阶段,我们则不需要反向传播更新网络参数,换句话说,mdoel_fn需要对三种模式设置三套代码。
Estimator规定model_fn需要返tf.estimator.EstimatorSpec,这样它才好更具一般化的进行处理。
RunConfig
此处的config需要传入tf.estimator.RunConfig,其源代码如下:
class RunConfig(object):
"""This class specifies the configurations for an `Estimator` run."""
def __init__(self,
model_dir=None,
tf_random_seed=None,
save_summary_steps=100,
save_checkpoints_steps=_USE_DEFAULT,
save_checkpoints_secs=_USE_DEFAULT,
session_config=None,
keep_checkpoint_max=5,
keep_checkpoint_every_n_hours=10000,
log_step_count_steps=100,
train_distribute=None,
device_fn=None,
protocol=None,
eval_distribute=None,
experimental_distribute=None,
experimental_max_worker_delay_secs=None,
session_creation_timeout_secs=7200):
- model_dir: 指定存储模型参数,graph等的路径
- save_summary_steps: 每隔多少step就存一次Summaries,不知道summary是啥
- save_checkpoints_steps:每隔多少个step就存一次checkpoint
- save_checkpoints_secs: 每隔多少秒就存一次checkpoint,不可以和save_checkpoints_steps同时指定。如果二者都不指定,则使用默认值,即每600秒存一次。如果二者都设置为None,则不存checkpoints。
- keep_checkpoint_max:指定最多保留多少个checkpoints,也就是说当超出指定数量后会将旧的checkpoint删除。当设置为None或0时,则保留所有checkpoints。
- keep_checkpoint_every_n_hours:
- log_step_count_steps:该参数的作用是,(相对于总的step数而言)指定每隔多少step就记录一次训练过程中loss的值,同时也会记录global steps/s,通过这个也可以得到模型训练的速度快慢。(天啦,终于找到这个参数了。。。。之前用TPU测模型速度,每次都得等好久才输出一次global steps/s的数据。。。蓝瘦香菇)
后面这些参数与分布式有关,以后有时间再慢慢了解。
- train_distribute
- device_fn
- protocol
- eval_distribute
- experimental_distribute
- experimental_max_worker_delay_secs
什么是tf.estimator.EstimatorSpec
传入参数
它是一个class(类),是定义在model_fn中的,并且model_fn返回的也是它的一个实例,这个实例是用来初始化Estimator类的。其源代码如下:
class EstimatorSpec():
def __new__(cls,
mode,
predictions=None,
loss=None,
train_op=None,
eval_metric_ops=None,
export_outputs=None,
training_chief_hooks=None,
training_hooks=None,
scaffold=None,
evaluation_hooks=None,
prediction_hooks=None):
重要函数参数:
- mode:一个ModeKeys,指定是training(训练)、evaluation(计算)还是prediction(预测).
- predictions:Predictions Tensor or dict of Tensor.
- loss:Training loss Tensor. Must be either scalar, or with shape [1].
- train_op:适用于训练的步骤.
- eval_metric_ops: Dict of metric results keyed by name. The values of the dict can be one of the following:
- (1) instance of Metric class.
- (2) Results of calling a metric function, namely a (metric_tensor, update_op) tuple. metric_tensor should be evaluated without any impact on state (typically is a pure computation results based on variables.). For example, it should not trigger the update_op or requires any input fetching.
不同模式需要传入不同参数
根据mode的值的不同,需要不同的参数,即:
- 对于mode == ModeKeys.TRAIN:必填字段是loss和train_op.
- 对于mode == ModeKeys.EVAL:必填字段是loss.
- 对于mode == ModeKeys.PREDICT:必填字段是predictions. 上面的参数说明看起来还是一头雾水,下面给出例子帮助理解:
最简单的情况: predict
只需要传入mode和predictions
# Compute predictions.
predicted_classes = tf.argmax(logits, 1)
if mode == tf.estimator.ModeKeys.PREDICT:
predictions = {
'class_ids': predicted_classes[:, tf.newaxis],
'probabilities': tf.nn.softmax(logits),
'logits': logits,
}
return tf.estimator.EstimatorSpec(mode, predictions=predictions)
评估模式 : eval
需要传入mode,loss,eval_metric_ops
如果调用 Estimator 的 evaluate 方法,则 model_fn 会收到 mode = ModeKeys.EVAL。在这种情况下,模型函数必须返回一个包含模型损失和一个或多个指标(可选)的 tf.estimator.EstimatorSpec。
loss示例如下:
# Compute loss.
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
TensorFlow提供了一个指标模块tf.metrics来计算常用的指标,这里以accuracy为例:
# Compute evaluation metrics.
accuracy = tf.metrics.accuracy(labels=labels,
predictions=predicted_classes,
name='acc_op')
返回方式如下:
metrics = {'accuracy': accuracy}
if mode == tf.estimator.ModeKeys.EVAL:
return tf.estimator.EstimatorSpec(
mode, loss=loss, eval_metric_ops=metrics)
训练模式:train
需要传入mode,loss,train_op
loss同eval模式:
# Compute loss.
loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)
train_op示例:
optimizer = tf.train.AdagradOptimizer(learning_rate=0.1)
train_op = optimizer.minimize(loss,global_step=tf.train.get_global_step())
返回值
return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=train_op)
通用模式
model_fn可以填充独立于模式的所有参数.在这种情况下,Estimator将忽略某些参数.在eval和infer模式中,train_op将被忽略.例子如下:
def my_model_fn(mode, features, labels):
predictions = ...
loss = ...
train_op = ...
return tf.estimator.EstimatorSpec(
mode=mode,
predictions=predictions,
loss=loss,
train_op=train_op)