Tesla AI DAY 技术情况
特斯拉感知

通过8个摄像头的输入 得到三维向量空间
Tesla Camera的分辨率 1280*960
信息架构借鉴了人脑视觉结构的设计
主干网络利用regnet进行设计 很好的平衡了延迟和准确性.
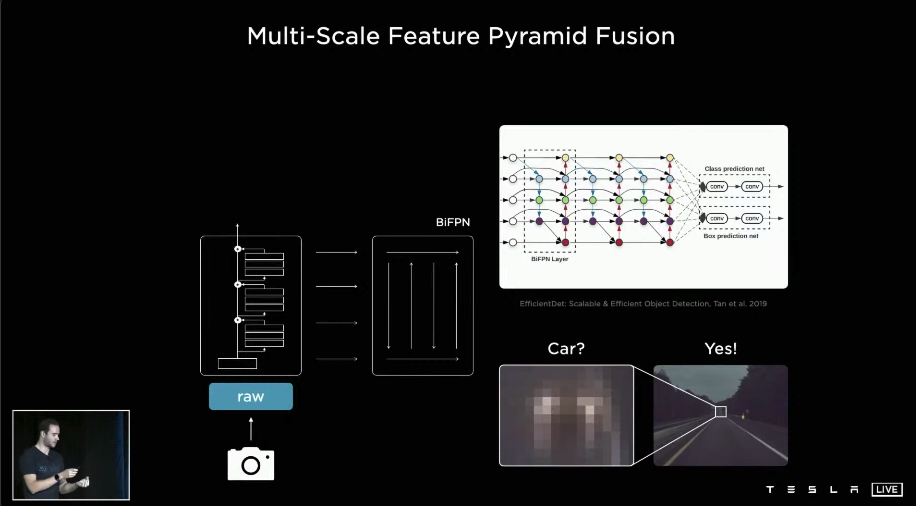
RegNet特征提取后,通过一个BiFPN进行特征融合
然后特征即可用于做分类和回归
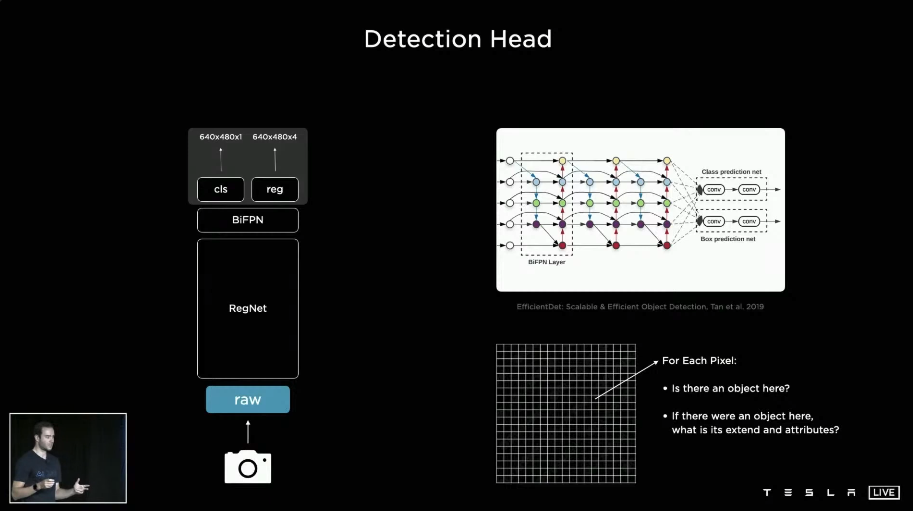
通过特征融合,衔接一个multi-scale features 可以做多任务的学习 其网络是HydraNets 通过一个主干网络 分支成为多个头部
这种网络架构的好处:
- 相互的特征共享
- 对头部的微调可以单独进行
- 设立Cache,加速Fine-Tuning
通过一个backbone可以做不同的Task 🐂🍺
Fine-Tune的概念
介绍了一个相机检测路沿的例子

Per-Camera Detection Then Fusion的方式使得检测不够连续
通过多摄像头建立Vector Space,然后利用空间向量进行Predictions
其中有两个问题:
- 如何将图像特征转换为空间向量特征
- 空间向量的预测需要空间向量的数据集
image_space -> vector space 图像上看到的点在鸟瞰坐标下如何对应的问题 对应结果是为了得到Vector space Head Edges
利用transformer整合多个Camera的特征 因为特征是不同车辆在不同摄像头下拍摄的 所以需要校准,这种校准用到了positional encoder 现实重建了一个虚拟相机 根据IMU的数据进行标定
栅格地图由图像生成 将图像反算3D 能在3D栅格地图上有效得到路沿的识别结果
detect before fusion 的方法 导致车道线 障碍物的检测不够连续 通过先融合feature,在prediction的方法,Vector Space Edges and Lines会更有效的串联多个图片的信息.
Detections:SingleCam -> MultiCam
Detections采用了相同的方式 从Single-Cam演变到Multi-Cam 更多的摄像头相互配合 会使得检测的视角更广 物体更平顺 结果更为优秀
我认为的大招 Video Neural Net Architecture模块
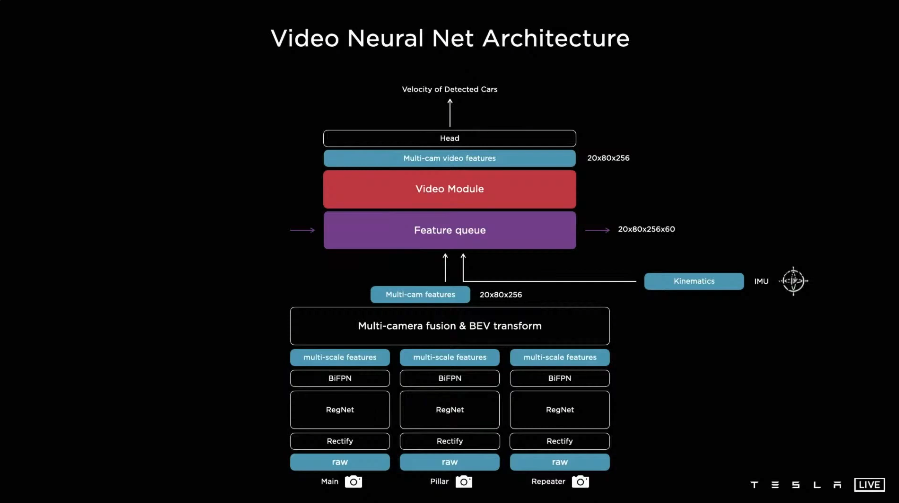
通过queue的列队插入 使得模型具有memory功能
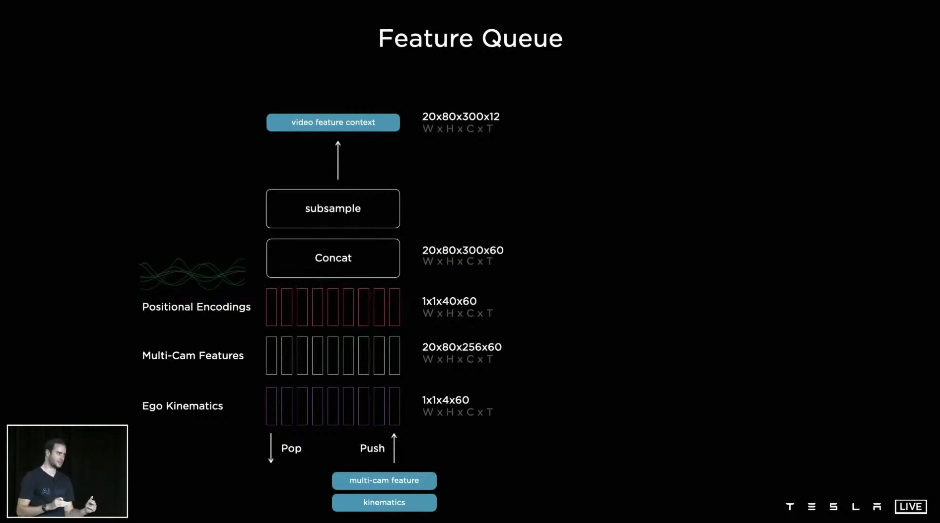
通过参考记忆,可以有效应对遮挡问题 🐂
应用方向 通过Spatial RNN做路径的预测,完全摆脱建图
应用方向2 提高对临时遮挡物体识别的鲁棒性
应用方向3 咱物体识别上也更为流程 特别是距离估计上 十分顺滑
整个Tesla感知层面的架构
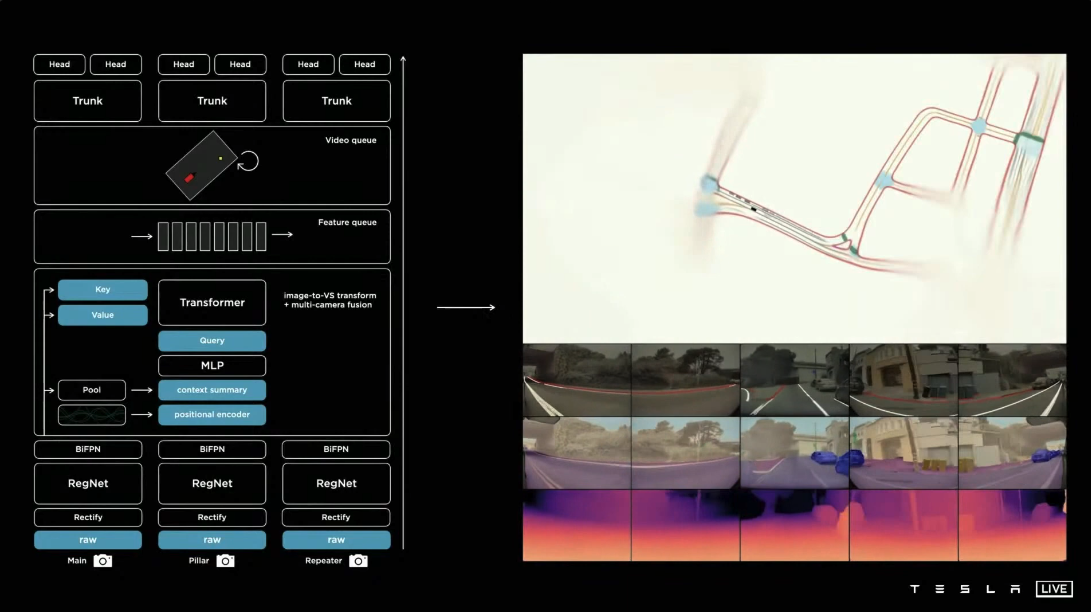
大致架构 原始数据输入,链接一个校正层校准相机数据,然后将数据投入到一个虚拟相机中,然后将数据传送到RegNet中,处理成不同尺度的features,将多尺度的信息在BiFPN中进行融合,通过转换模块将其表示为向量空间,将时间或空间中的特征序列化为Feature queue,然后输入到视频处理模块,处理后的features,进入树干和头部分支,去完成不同的任务. 这个网络也是从图片识别的简单网络,通过三四年的迭代发展而来的.
最大的创新点是在时间和空间上进行了融合
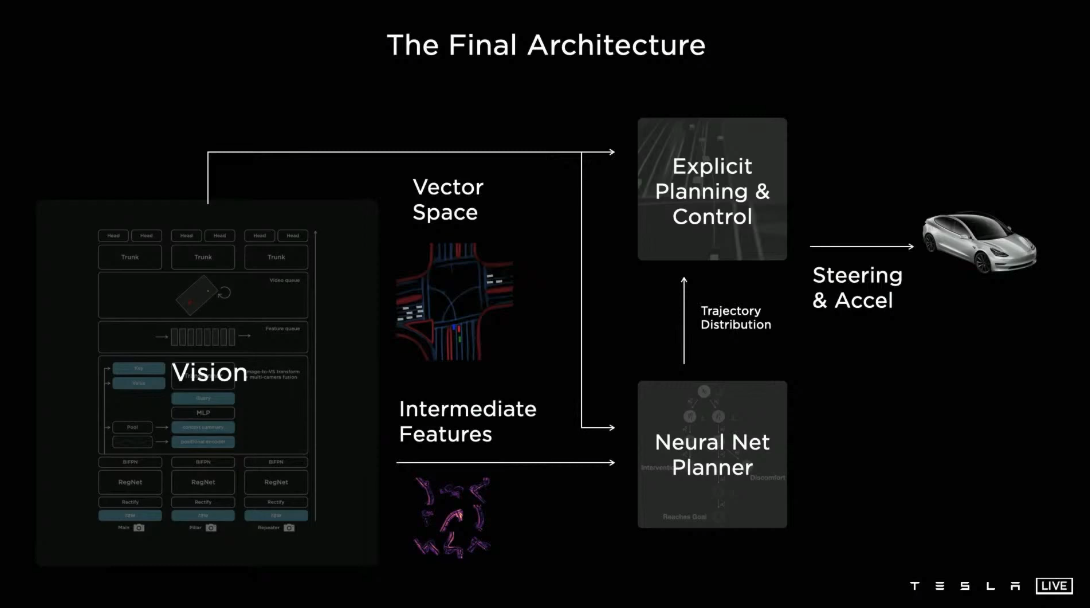
整个特斯拉技术栈的架构 后期视频逐步看完后更新.
- RegNet 论文
- BiFPN 论文 < EfficientDet: Scalable and Efficient Object Detection>
- HydraNets 论文 <Mullapudi_HydraNets_Specialized_Dynamic_CVPR_2018_paper>
- Heuristic neural net 论文