Lane detection研究报告
内容主要包含两部分
- 对于视频分享的要点的整理
- 对于视频中提到的论文阅读的整理(【极市】方浩:车道线检测新SOTA,RESA:循环特征位移聚合器(AAAI2021))
- 对于项目工程的整理(未开展)
Section A
Detect several lanes from image (front camera)
In planning stage:
- Trajectory planning
- Behavior prediction
- Lane keeping
Problem define:
- Input Image [3 x H x W]
- Output:N x lanes (instances,points,parameters,etc)
Key Challenges:
- Severe occlusion & ambigous lanes
- Sparse superisory signals inherent in lane annotations
- Real-time
Related work
Hough transform
- RGB -> Gray
- Gaussion blur
- Canny Edge Detection
- Hough transform
LaneNet
- Instance segmentation
- Pixel embedding + clustering
Towards end-to-end lane detection:an instance segmentation approach
SCNN
- RNN-like information passing
- Segmentation + post-process
Spatial as deep:Spatial cnn for traffic scene understanding
light-weight
- self-attention distillation(SAD)
- CurveLane-NAS
CurveLane-NAS:Unifying Lane-Sensitive Architecture Search and Adaptive Point Blending
Gridding
- Pixel -> cell
- Row-wise classification
- High speed but accuracy is lost
Ultra Fast Structure-aware Deep Lane Detection End-to-End Lane Marker Detection via Row-wise Classification Inter-Region affinity Distillation for Road Marking Segmentation
PolyLaneNet
Lane Estimation via Deep Polynomial Regression
Lane Estimation via Deep Polynimial Regression
Anchor-based
- Strong prior
- Not flixible to handle various cases
Keep your Eyes on the Lane:Real-time-Attention-guided Lane Detection
Why classical sematic segmentation does not work?
- Severe occlusion & ambigous lanes
- Sparse superisory signals inherent in lane annotations(thin and long)
idea:
-
Strong shape priors(continuous)
-
Spatial correlation
-
Slicing
-
Information passing in horizontal and vertical directions
- Encoder
- RESA
- Decoder
- conv1x1
Section B
Keep your Eyes on the Lane:Real-time-Attention-guided Lane Detection
论文地址:https://arxiv.org/pdf/2010.12035.pdf Github地址:https://github.com/lucastabelini/LaneATT
Abstract
现有车道线检测方法在复杂的现实世界场景中已取得了卓越的性能,但是许多方法都存在运行实时效率的问题,这对于汽车的自动驾驶来说至关重要。在这项工作中,我们提出了LaneATT:基于anchor的深度车道线检测模型,类似于其他通用的深度目标检测器,该模型将anchors用于特征池化步骤。由于车道线遵循规则的模式并高度相关,因此我们假设在某些情况下,全局信息对于推断其位置可能至关重要,尤其是在诸如遮挡,缺少车道标记等情况下。因此,我们提出了一种新颖的基于anchor的注意力机制,该机制聚集了全局信息。在文献中使用最广泛的数据集对模型进行了广泛的评估。结果表明,我们的方法优于当前的最新方法,显示出更高的功效和效率。此外,我们进行了消融研究,并讨论了在实践中有用的效率折衷方案。
Introduction
本文在Line-CNN的基础上,提出了一个速度与性能兼备的车道线检测模型。主要贡献如下:
1.在大型和复杂的数据集上,本文提出的车道检测方法比现有的最新实时方法更准确;
2.具有比大多数其他模型更快的训练和推理时间的模型(达到250 FPS的速度,并且比以前精度最高的方法的MAC少近一个数量级);
3.一种新颖的基于anchor的车道检测注意机制,该机制在与检测到的物体相关的其他领域可能很有用。
LaneATT
使用从安装在车辆中的前置摄像头拍摄的RGB图像作为输入。 输出是车道线。 为了生成这些输出,卷积神经网络(CNN)(称为主干)会生成一个特征图,然后将其汇总以提取每个anchor的特征。 这些特征与注意力模块生成的一组全局特征结合在一起。 通过结合局部和全局特征,该模型可以更轻松地使用来自其他车道的信息,这在有遮挡或没有可见车道标记的情况下可能是必需的。 最后,将合并的特征传递到全连接层以预测最终的输出通道。

A.Lane and anchor representation

Lane的anchor表征方式与Line-CNN的方式一致。如上图所示,首先将特征图均分为一定大小的网格。然后,一条lane由起始点s和结束点e,以及方向a组成。也就是一条lane由起始点按照一定方向到结束点的所有2d坐标组成。
B.Anchor-based feature pooling
两阶段的目标检测算法会把一定矩形区域的anchor特征池化到一定长度的特征,以用于后面的卷积或全连接层进行预测。对于车道线而言,因为lane的anchor表征不再是矩形区域,而是一条线。因此本文提出了如下公式

x_orig,y_orig是起始点的坐标,θ \thetaθ是线的角度方向。这个公式的意思也比较好理解,就是按照网格y坐标找出line上的对应x坐标,这样就可以挑出固定长度的特征出来,长度为特征图F的高度。如果出现了y对应的x点坐标在特征图外,就采用padding的方式补齐。

pooling操作与Fast R-CNN的感兴趣区域投影(RoI投影)类似,但是,考虑到本文的方法是单级检测器,因此使用anchor本身,而不是使用proposal 进行pooling。此外,RoI池化层(用于生成固定大小的特征)对于我们的方法不是必需的。 与仅利用特征图边界的Line-CNN 相比,本文的方法可以潜在地浏览所有特征图,从而可以使用更轻量的主干和较小的感受野范围。
C.Attention mechanism
上面pooling出的特征只是车道线上的局部特征,在遇到车道线遮挡的情况下,还需要全局特征才可以更好的进行预测。因此,本文提出了一种注意力机制,该机制作用于局部特征(αloc)以产生汇总全局信息的附加特征(αglob)。
公式如2所示,对于池化得到的i和j两个anchor的局部特征,使用Latt(全连接层)去预测i和j的关系。相当于基于当前局部特征i,去预测它和其他局部特征的权重关系,然后聚合其他特征来作为全局特征。

D. Proposal prediction
基于上面提取到的局部特征(αloc)和全局特征(αglob)。预测分支有两个,分类分支去预测k+1个类别,k个车道线类别和1个背景类别。回归分支基于anchor的起始点s,预测出N个点的坐标与anchor的偏移,以及一个线的长度L。因此,车道线的结束点就是e = s+l-1。
E.NMS
NMS的过滤阈值采用两条车道线的公共y坐标的距离。

Experiments:
SOTA On TuSimple:

推理速度的对比

End-to-end Lane Shape Prediction with Transformers
论文地址:https://arxiv.org/pdf/2011.04233.pdf Github地址:https://github.com/liuruijin17/LSTR
Abstract
车道检测是将车道标记识别为近似曲线的过程,被广泛用于自动驾驶汽车的车道偏离警告和自适应巡航控制。流行的分两步解决问题的pipline-特征提取和后处理虽然有用,但效率低下,而且在学习全局背景和车道的细长结构方面存在缺陷。为了解决这些问题,我们提出了一种端到端方法,该方法可以直接输出车道线形状模型的参数,使用通过transformer构建的网络来学习更丰富的结构和上下文。道线形状模型是基于道路结构和摄像头姿势制定的,为网络输出的参数提供了物理解释。transformer使用自注意机制来建模non-local交互,以捕获细长的结构和全局上下文。该方法已在TuSimple基准测试中得到验证,并以最轻巧的模型尺寸和最快的速度显示了最新的准确性。此外,我们的方法对具有挑战性的自收集车道检测数据集显示出出色的适应性,显示了其在实际应用中的强大部署潜力。
Intruduction
本文提出将车道检测输出重新构造为车道线形状模型的参数,并提出使用non-local构造块构建的网络,以加强对全局背景和车道细长结构的学习。 每个车道的输出是一组参数,这些参数使用从道路结构和摄像头姿态得出的明确数学公式来近似车道标记。

给定特定的先验条件,例如摄像机固有特性,这些参数可用于 计算道路曲率和 摄像机俯仰角,而无需任何3D传感器。 接下来,受自然语言处理模型的启发,该模型广泛使用transformer来对语言序列中的远程依存关系进行显式建模,我们开发了基于transformer的网络,该网络总结了任何成对视觉特征中的信息,从而能够捕获车道的长 薄薄的结构和全局上下文。 整个体系结构可立即预测输出,并接受匈牙利损失的端到端训练。 该损失在预测和gt之间应用了二分匹配,以确保一对一的无序分配,从而使模型可以消除显式的nms过程。
主要贡献
1.本文提出了一种车道线形状模型,其参数可作为直接回归的输出并反映道路结构和摄像机的姿态。
2.我们提出了一个基于transformer的网络,该网络考虑了non-local交互以捕获车道和全局上下文的细长结构。
3.本文方法以最少的资源消耗实现了最先进的精度,并显示出对新的具有挑战性的自收集车道检测数据集的出色适应性。
Experiments
SOTA On TuSimple:

SCNN: Spatial CNN for Traffic Lane Detection
前言
车道线检测在自动驾驶感知任务中占据重要的一席,它可以辅助自动驾驶的车道保持,同时也可以为车辆定位等工作提供较强的先验信息。目前,常见的方法大抵是基于路面的语义分割(如:FCN等)对车辆相机捕捉的画面可视范围中的车道线,进行分类及分割检测,以辅助实现车辆自动驾驶的车道保持等功能。而SCNN的创新点同时也是值得学习的地方是,它清晰定义了车道线算法需要处理的车道线范围(至多检测四条车道线),同时将交通规则融入数据标注中,也较好地规避了路面遮挡等情况对车道线检测的负面影响。当然它也存在一些弊端,比如使用的切片处理(文中后续会详细解释)在落地方面较难优化,特殊的语义定义有些待处理的弊端。
1.摘要
CNN模型在语义分割上展现出了强大的潜力,但它对于图像的行间、列间的空间处理能力还有待发掘。这类空间关系对于有显著的形状和空间约束、并且表观特征比较单一的检测目标非常重要。车道线检测正好符合以上的目标约束.
以此为入口,作者提出了SCNN,该算法对feature进行切片处理再进行逐层卷积,使得特征可以按行或按列方向有效地传递。SCNN的这个特点使得其对长条形的检测目标很有优势,下图对比发现,该算法较CNN模型而言可以在遮挡及路面磨损的情况下获得较好的结果,在语义分割任务中,对长条形的路杆同样可以处理的更好。

2.背景介绍及研究现状
自动驾驶在学术上和工业界里都获得了大量的关注。自动驾驶系统中一个重要的任务是理解道路场景,包括车道线检测、语义分割等等。车道线检测算法可以辅助自动驾驶车辆自动行驶,并且已经被应用到车辆驾驶辅助系统中。与通用的语义分割不同的是,车道线检测任务中我们面临的问题是,车道线具有较强的结构特征:
- 车道线通常呈放射相邻状;
- 车道线通常会被遮挡. 按照传统的语义分割算法的处理模式,只处理可见区域的车道线,遮挡的部分不能被检测,在道路状况相对拥挤的情况下,检测性能定会大大降低。
为了较好地解决遮挡问题导致的精度下降,作者提出了SCNN算法。在SCNN中,比较核心的创新点在于作者提出对 backbone网络输出的特征矩阵进行切片处理,并且对其进行逐行或逐列方向上的一维卷积操作。这个设计有利于 传递细长形的目标特征,如车道线或路杆等。而且,这个切片设计可以很好地解决遮挡问题,尽管车道线会被部分遮挡,只要有可见的部分,SCNN都可以较好地将车道线整条地预测出来。
在深度学习普及前,大部分的车道线检测算法都是基于人为设计的特征处理的,对很多复杂的场景处理的都不太好。Huval等人在2015年将深度学习和车道线检测结合在一起,不过仅基于一个不太大的数据集。然而,深度学习在语义分割方向的应用近年来取得了很大的进展。在挖掘神经网络的空间特征方面,也有人尝试使用RNN将每行或每列的特征传递,然而仅限于同行或同列的信息传递。Liang等人也提出使用LSTM来进行语义分割,但是这类方法的计算代价较大。在语义分割方面,研究者们也倾向于将CNN和CRF或MRF进行结合,我的个人感觉是传统方法的延续性做法。
分析了这么多研究现状后,说一下SCNN的三个主要优点。
1)相比使用传统的MRF/CRF做后处理,SCNN在空间特征的捕捉上更有效。
2)从训练的角度分析,SCNN中的切片处理将特征信息以叠加的方式进行传递(参见ResNet,原文用的是residual这个词),因而更容易训练和收敛。
3)SCNN这种特殊的结构很灵活,可以应用到其他的深度学习任务中。
3.方法SCNN
3.1 车道线监测数据集CULane
SCNN相较于其他的车道线检测算法的优点在于将检测范围清晰定义,至多只会检测当前道路的四条车道线。SCNN的输出为左二线、左一线、右一线和右二线,分别对应为蓝色、绿色、红色和黄色标注的线。并且,前言中也提到,SCNN将待检测的四条车道线与交通规则结合。这两个特点主要体现在本文release的CULane数据集。该数据集包含了超过8万张图,涵盖常见场景(Normal)、拥挤场景、夜晚场景等9个场景的数据,各个场景所占比.

CULane数据集中,每帧数据都包含需要检测的车道线的标注值及每条车道线对应的标签(左二线、左一线、右一线和右二线)。之前提到的SCNN的两个优点,一个是遮挡方面的问题,数据的标注规则中将遮挡的车道线预测标注,这样使得SCNN在处理遮挡的数据时,仍可以较好地预测出遮挡的车道线部分。另一方面,标注规则将交通规则融合,如Y形线或人行横道处,车道线对应停止标注。
3.2 Spatial CNN
传统的分割方法通常会使用CRF/MRF来对其分割结果进行后处理。然而,这样的两段式后处理pipeline不是很有利于在抽取特征阶段就挖掘和利用图像的空间特征。而作者提出的SCNN可以更好更有效地学习到车道线的空间信息,是一个端到端的方法。下图为SCNN的整体流程示意图。

下面具体给出SCNN的特殊切片设计。如图3-2所示,我们就SCNN_D部分进行具体解释。在backbone基础网络处理后,我们得到的特征矩阵为CHW,其中C、H和W对应着特征矩阵的channel(通道)、height(高度)、width(宽度)。在SCNN_D处理环节中,我们将这个特征矩阵按行切片,即得到H个特征切片,如图中所示。第一片特征经一维的卷积操作后,从上向下叠加传递,类似于ResNet的处理方式,第二片特征加上第一片特征的卷积输出后,进行一维卷积操作,以此向下传递,直到最后一片特征处理完毕。该特征矩阵传递到下一个处理模块SCNN_U。SCNN_D表示从上向下处理,SCNN_U代表从下向上,SCNN_R则表示从左向右,SCNN_L表示从右向左。
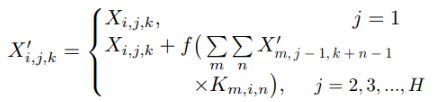
切片的处理过程公式化如上所示。经过四个SCNN模块处理后,特征矩阵(CHW)经过再一次卷积操作,输出为n个通道的分割结果。由于backbone中对原图有下采样操作,最后进行像素级别的损失函数计算前,作者对图像进行了对应倍数的上采样放大操作。
结果
SCNN的实验主要在CULane数据集和Cityscapes上进行。训练技巧上,作者使用标准的SGD,batch size为12,0.01的初始化学习率等。更多的训练细节请参考原文。
4.1 模型的推断和输出
车道线检测任务的输出通常对接精确的曲线拟合。如图4-1所示,SCNN模型的输出为4个分割mask,分别对应左二线、左一线、右一线和右二线的标签。另一方面,SCNN还会输出一个1*4的一维向量,以指示是否存在对应类别车道线,如[0, 1, 1, 1],则说明该输入的图像中只包含左一线、右一线和右二线,左二线的存在标签为0则意味着不存在左二线。根据该一维向量,作者对SCNN的输出mask进行处理,最后用三次样条曲线来拟合最终的车道线曲线。

4.2 模型评估
为判断每条车道线是否被正确检测,作者将每条车道线视为30像素宽的线状前景。评估过程中,计算预测结果mask和真值mask之间的交并比(IoU)。当交并比超过设定的阈值时,则判断为检测正确。实验中,作者使用了0.3和0.5作为评估阈值。如图4-2所示,正确的车道线标注为蓝色,错误检测的车道线标注为红色。

5. 结论
SCNN算法的特殊切片设计使得其对细长型的分割目标具有更好的空间关系学习能力,也可以更好的处理路面遮挡、磨损等情况。总体说来,SCNN在车道线检测领域方向上,开辟了一种新的思路,很值得学习和借鉴。另外,作者的git repo给的非常完备,源代码使用lua torch实现.
Towards End-to-End Lane Detection: an Instance Segmentation Approach
论文链接:https://arxiv.org/abs/1802.05591 代码链接:https://github.com/MaybeShewill-CV/lanenet-lane-detection (tf实现,并不完整,部分功能未实现)
主要贡献是两点,一个是利用Semantic Instance Segmentation with a Discriminative Loss Function的思路来实现对任意数量车道线的检测;另一个是车道线检测往往要通过变换矩阵来进行角度变换来使车道线平行从而拟合出可靠的车道线数学模型,但是固定的变换矩阵参数难以适应不同图片或者图片中的地平线变化,作者通过CNN学习矩阵参数解决了这个问题。面临类似问题的同学不妨一读。
Introduction
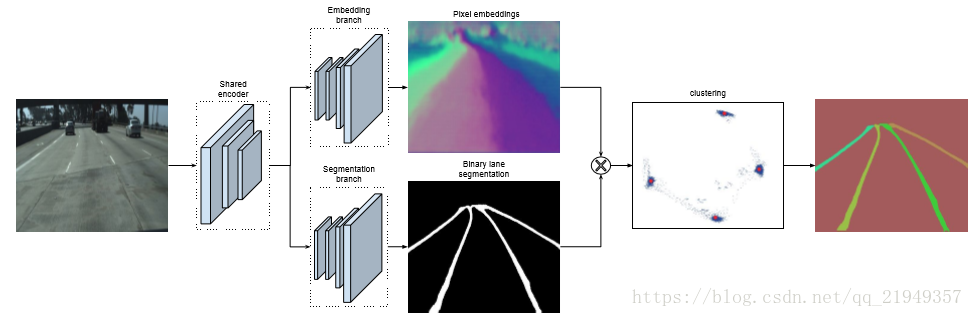
车道线检测实际上属于自动驾驶算法范畴的一部分,可以用来辅助进行车辆定位和进行决策等等。由于车道线本身狭长和弯曲的特性,实际上这个问题更合适看作分割问题而不是检测问题。 如果只是检测固定数量的车道线,可以将不同车道线看作不同的类别,比如左车道线类、右车道线类和背景类等等……但是,如果车道线数量是不固定的呢?无论是常见的对pixel进行softmax分类或者decouple的多个二分类,似乎都没办法解决这个问题了。这个问题其实更像是semantic instance segmentation,不仅要分类,还要精确描述每个个体。 在这里,作者应用了Semantic Instance Segmentation with a Discriminative Loss Function中的思路;同时利用CNN网络来预测车道线的mask,并对所有属于车道线的像素点进行聚类,得到不同的车道线,示意图如下……
再拟合每条车道线的数学模型
2.Method
LaneNet
首先是主体网络部分,两条分支,一条分支预测mask,另一条分支给每个lane pixel分配所属lane的id。 binary segmentation 和常规的分割问题一样,没有太多特别的。值得一提的是,无论是车道线还是虚线或者车道线被遮挡的情况,作者在生成ground truth的时候都把它们标注了出来,这样就算对车道线没有完全露出来的情况,网络也可以比较好的学习。 重点是instance segmentation 分支,这个就是利用了上面提到的那篇文章的设计思路,分支的设计思想和传统统计学习的很多算法都类似,不同的lane看作不同的类,而预测的结果力求类内最小化和类间最大化。本着这个原则设计了loss函数。
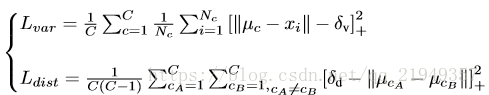
第一项的主要作用就是把属于同一条lane的像素点往一起推,如果像素点和中心点距离超过一定阈值,就会产生loss;第二项的作用是把不同类中心点往距离加大的方向拉,如果中心点之间的距离小于一定阈值,就会产生loss(+号的意思代表若大于等于0不变,否则看作0),关于这两个阈值怎么选具体可以看论文,作者的设置和原文有一定的差别。 有了这个loss函数,就可以根据lane的mask和不同lane的像素点集合进行训练了。inference的时候思路如下:随机选取一个lane pixel视作当前lane的点集,然后将周围和它距离小于类内点阈值的所有点视作同一类,然后再遍历其它点,如果有某个点和点集内任意点距离小于类内阈值,则将该点加入点集,重复该过程直到点集不再发生变化,给这些点集分配一个lane的id;然后再选取没有被分配id的任意一个pixel,重复该过程。 关于network architecture,作者用的是 encoder-decoder ENet,这个网络共有三个阶段,这两个分支共享前两个阶段,而第三个阶段的encoder和整个网络的decoder部分则是独立
curve fitting
车道线检测一般是给y轴坐标,求车道线上对应的点的x轴的值。仅仅求出所有lane pixel是不够的,还要进行直线拟合,求出对应的数学模型。一般来说,现在在拟合曲线时候都会把图像转化到bird’s-eye view角度,就是让车道线都平行,这些便于拟合、可靠性更高,然后求出相应的点后,再映射回来。 转化到bird’s-eye view是利用矩阵来求的,问题来了,这个矩阵一般是计算一次后就对所有图像都使用的,一个问题就是,如果地平线发生变化,比如汽车行驶在山峦的公路上,很容易产生误差,因此作者就利用一个CNN网络,作者称之为H-Net来学习相关参数。
3. 实验结果
基于学习方法的投影方法H-Net
将输入的RGB图像作为输入,使用LaneNet得到输出的实例分割结果,然后将车道线像素使用H-Net输出得到的透视变换矩阵进行变换,对变换后的车道线像素在变化后的空间中进行拟合,再将拟合结果经过逆投影,最终得到原始视野中的车道线拟合结果。
H-Net将RGB作为输入,输出为基于该图像的透视变换系数矩阵,优化目标为车道线拟合效果[41]。
50帧/秒进行端到端车道检测的方法。受到最近实例分割技术的启发,与其他相关的深度学习方法相比,我们的方法可以检测可变数量的车道并且可以应对车道变换。为了使用低阶多项式对分段车道进行参数化,我们已经训练了一个网络来生成透视变换的参数,以图像为条件,其中车道拟合是最优的。与流行的“鸟瞰视图”方法不同,我们的方法通过调整相应地参数进行变换,可以有效抵抗地平面的坡度变化。
PolyLaneNet Lane Estimation via Deep Polynomial Regression
通过深度多项式回归的车道估计
Abstract
自主驾驶取得巨大进步的主要因素之一是深度学习的出现。对于更安全的自动驾驶车辆,车道检测是尚未完全解决的问题之一。由于该任务的方法必须实时工作(+30 FPS),因此它们不仅必须有效(即具有高精度),还必须高效(即快速)。在这项工作中,我们提出了一种新的车道检测方法,该方法使用来自安装在车辆中的前视摄像机的图像作为输入,并通过深度多项式回归输出表示图像中每个车道标记的多项式。所提出的方法在保持效率(115 FPS)的同时,在TuSimple数据集中与现有的最先进的方法相比具有一定的竞争力。此外,还提供了另外两个公共数据集的大量定性结果,以及最近车道检测工作中使用的评估指标的局限性。最后,我们提供源代码和经过训练的模型,允许其他人复制本文中显示的所有结果,这在最先进的车道检测方法中是非常罕见的。
github代码:https://github.com/lucastabelini/PolyLaneNet
Introduction
自动驾驶[1]是一个富有挑战性的研究领域,近年来备受关注。与该领域相关的感知问题已经受到深度学习进展的极大影响[2]–[4]。特别是,自动车辆应该能够估计车道,因为除了作为空间限制之外,每条车道都提供了控制行驶的特定视觉线索。在这种情况下,两条最重要的交通线(即车道标线)是那些定义车辆车道的线,即自我车道。这些线为驾驶员的行动设置了限制,它们的类型定义了是否允许机动(例如,换道)。此外,检测相邻车道可能是有用的,这样系统的决策可能基于对交通场景的更好理解。
车道估计(或检测)起初可能看起来微不足道,但它可能非常具有挑战性。尽管车道标志相当标准化,但其形状和颜色各不相同。当出现虚线或部分遮挡的车道标志时,估计车道需要对场景的语义理解。此外,环境本身是多种多样的:可能有大量的交通,人们经过,或者它可能只是一条高速公路。此外,这些环境受多种天气的影响(例如,下雨、下雪、晴天等)。)和照明(例如,白天、夜晚、黎明、隧道等。)条件,这可能会在驾驶时发生变化。
在这种情况下,专注于消除对两步处理过程的需求,并进一步降低处理成本的方法可以使依赖于低能耗和嵌入式硬件的高级驾驶辅助系统受益。此外,一种已经在美国以外的道路上测试过的方法也对更广泛的社区有益。此外,不太宽松的度量标准将允许更好地区分方法,并提供对方法及其有用性的更清晰的概述. 这项工作提出了PolyLaneNet,用于端到端车道标线估计的卷积神经网络。PolyLaneNet从安装在车辆中的前视摄像机获取图像作为输入,并输出表示图像中每个车道标志的多项式,以及这些多项式的域和每个车道的置信度得分。 这种方法与现有的最先进的方法相比具有竞争力,同时速度更快,并且不需要后处理来进行车道估计。此外,我们使用文献中建议的指标提供了更深入的分析。最后,我们公开发布了源代码(用于训练和推理)和经过训练的模型,允许复现本文中给出的所有结果。
RELATED WORDS
车道检测。在深度学习兴起之前,车道线检测的方法大多是基于模型或学习的,也就是说,它们利用手工制作和专门的特征。形状和颜色是最常用的特征[10],[11],车道通常由直线和曲线表示[12],[13]。然而,这些方法对突然的光照变化、天气条件、摄像机之间的外观差异以及驾驶场景中的许多其他情况都不稳定。有关早期车道检测方法的更完整调查,请参考[5]中感兴趣的读者。 随着深度学习的成功,研究人员也研究了它在车道检测中的应用。Huval等人[14]是最先在车道检测中使用深度学习的人之一。他们的模型基于OverFeat,并产生一种分割图作为输出,该分割图随后使用数据库扫描聚类进行后处理。他们在旧金山(美国)收集了一个私人数据集,用来训练和评估他们的系统。由于他们的成功应用,公司也有兴趣研究这个问题。后来,福特发布了Deeplane[15],与大多数文献不同,它基于横向安装的摄像头来检测车道。尽管结果不错,但他们模拟问题的方式使其不太适用,而且他们还使用了一个基于美国的私人数据集。 最近,在CVPR 17 举行了车道检测挑战赛,发布了TusSimple[16]数据集。挑战的获胜者是SCNN [7],这是一种被提议用于交通场景理解的方法,它通过特别设计的CNN结构利用空间信息的传播。他们的模型输出车道概率图,以提供后处理时的车道估计。为了评估他们的系统,他们使用了一个基于预测和Ground truth之间的IoU的评估标准。在此之后,在[8]中,作者提出了Line-CNN模型,该模型的关键部分是line-proposal unit(LPU),该单元改编自Faster-RCNN中的RPN。他们还将他们的结果提交给了TuSimple benchmark(在挑战结束后),结果比SCNN略好。然而,他们的主要实验是使用一个更大的数据集,这个数据集没有公开发布。除了这个私有数据集,源代码是私有的,作者不会发布它。另一种方法是FastDraw [17],在这种方法中,基于基础分割的后处理方法被替换为根据在训练中最大化的折线的可能性来“绘制”车道。除了在TuSimple和CULane [7]数据集上进行评估,作者还在另一个基于美国的私有数据集上提供了定性结果。此外,他们没有发布他们的实现,这阻碍了进一步的比较。一些基于分段的方法集中于提高推理速度,如[9] (ENet-SAD),其集中通过利用自我注意提取特征来学习轻量级的CNNs。作者在三个著名的数据集上评估了他们的方法。虽然源代码是公开发布的,但有些结果是不可复现的。更接近于我们的工作,[18]提出了一个可微的最小二乘拟合模块来拟合由深度神经网络预测的点上的曲线。在我们的工作中,我们通过直接预测多项式系数来避开对该模块的需求,这简化了方法也提高了速度。总之,现有方法的主要问题之一是可重复性,因为大多数方法要么不发布所使用的数据集,要么不发布源代码。在这项工作中,由于我们提供了源代码,并且只使用公开可用的数据集(包括一个来自美国以外的数据集),因此我们呈现的结果在公开数据集上与最先进的方法具有竞争力,并且完全可再现。

3.POLYLANENET
Polynomial Degree. 在大多数车道标志检测数据集中,曲率更明显的车道标志更少,而直线标志代表了大多数情况。考虑到这一点,人们可能会问:用低阶多项式模拟车道标线会有什么影响?为了帮助回答这个问题,我们的方法是使用一阶和二阶多项式来评估的,而不是默认的三阶多项式。此外,我们还通过计算不同阶多项式的上界,展示了文献中所用的标准TuSimple度量的允许性。 Ablation Study. 为了调查对所提出的方法做出的一些决定的影响,进行了消融研究,仅使用TuSimple的训练集进行训练,使用验证集进行测试。对于模型主干f(,θ),对ResNet [23]的两个变体进行了评估:ResNet-34和ResNet-50。 EfficientNet的另一个变种也被评估, EfficientNet-b1。此外,在训练CNNs时,除了主干的影响外,在使用不同的图像输入尺寸时也有一个权衡。例如,如果使用较小的输入大小,网络转发会更快,但是信息可能会丢失。为了在所提出的方法中测量这种折衷[22],训练了另外两个模型,一个使用480 × 270像素的输入尺寸,另一个使用320 × 180像素的输入尺寸。此外,还评估了其他三个实际决策: (一)不共享h的影响(即,单独预测每个车道的终点), (二)使用预先训练的模型,通过从头开始训练,而不是在ImageNet上预先训练模型;以及 (三)通过移除在线数据增加,使用数据增加的影响,这减少了模型在训练时看到的可变性。
4. result
PolyLaneNet对靠近摄像机的车道标志部分的预测(在那里可以看到更多细节)非常准确。尽管如此,在靠近地平线的车道标志部分,预测不太准确。我们推测这可能是数据集不平衡导致的局部最小值的结果。由于数据集中的大多数车道标志可以用一阶多项式(即线)很好地表示,所以神经网络倾向于预测直线,因此在具有突出曲率的车道标志上表现不佳。


5. 结论
提出了一种基于深度多项式回归的车道线检测新方法。与最先进的方法相比,所提出的方法简单有效,同时保持了有竞争力的准确性。尽管存在精确度稍高的最先进方法,但大多数方法都不提供源代码来复制它们的结果,因此很难对方法之间的差异进行更深入的研究。我们的方法,除了计算效率高之外,还将是公开的,以便将来在车道标线检测方面的工作有一个开始工作和比较的基线。此外,我们还发现了用于评估车道标线检测方法的指标存在问题。对于未来的工作,可以探索可用于不同车道检测方法(例如,分割)的度量,以及更好地突出车道检测方法中的缺陷的度量。