深度学习模型提取特征
有时候需要从图片中提取出数值型特征,供各种模型使用。 深度学习模型不仅可以用于分类回归,还能用于提取特征。通常使用训练好的模型,输入图片,输出为提取到的特征向量。
深度学习模型一般有N层结构,不能确定求取哪一层输出更合适。 深度学习模型很抽象——几十层的卷积、池化、信息被分散在网络参数之中。提取自然语言的特征时,常常提取词向量层的输出作为特征,有时也取最后一层用于描述句意;图像处理时往往提取最后一层输出向量;在图像目标识别问题中,常提取后两层子网络的输出作为组合向量。如何选择提取位置,取决于对模型的理解,后文将对图像处理层进行详细说明。
通常下载的ResNet,VGG,BERT预训练模型,虽然通用性高,但解决具体问题的能力比较弱。 用自己的数据fine-tune后往往更有针对性,而fine-tune的目标也需仔细斟酌,否则可能起到反作用。比如希望用ResNet识别不同的衣服,就需要考虑到衣服的形状、质地、颜色等等因素,如果用衣服类型(大衣、裤子)的分类器去fine-tune模型,新模型可能对形状比较敏感,而对材质、颜色的识别效果反而变差。
原理
图像模型ResNet-50规模适中,效果也很好,因此被广泛使用。下面将介绍该模型各层输出的含义,以及用它提取图片特征的方法。
ResNet原理详见论文:https://arxiv.org/pdf/1512.03385.pdf。 常用的ResNet网络参数如下,可以看到,包含四层Bottlenetct(子网络),越往后,获取的特征越抽象.

输入模型的图像结构为[1,3,224,224],图片大小为224x224(大小根据具体图片而定,有红绿蓝3个通道)

第一步,经过一个7x7卷积层,步长为2,它的输出是:(1,64,112,112),可视为64通道的112x112大小的图片,处理后效果如下图所示。

该层共生成64张图片,由于步长是2,大小变为112x112,每一种特征提取方法对应一组参数,这些参数对每7x7个像素进行同样处理,最终生成一个新的像素。换言之,就是构造了64种特征提取方法,分别提取了颜色,形状,边缘等特征,也可以看到由于处理以卷积为基础,图像位置关系得以保留。
在输入一张图片时,一个224x224的图通过这一层,提取了64x112x112=802816维特征,该层一般称为第一组卷积层conv1,由于该层次太过底层,维度过大,很少使用该层特征。
经过第一层之后,又经过归一化,激活函数,以及步长为2的池化,输出大小为[1, 64, 56, 56],如下图所示:
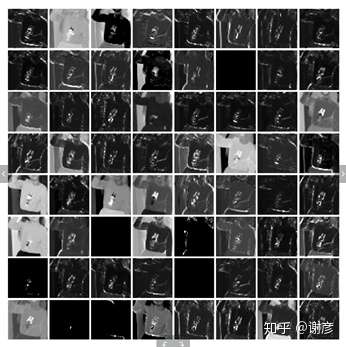
然后依次传入四个Bottlenext子网络(原理同上),分别称为conv2, conv3, conv4, conv5(也有名为layer1,layer2,layer3,layer4),输出的大小也逐层递减,最终减致2048x7x7=100352,长宽分别是原始参数的1/32。Mask-RCNN中就可获取R-50的第4和第5次作为特征。四层输出如下:

第一维是图像的张数,第二维是通道数,后两维分别是图片的宽高,从任一通道取出数据,都可以直接绘制该通道的图像。数据流至最后一个子网络conv5后输出是2048个7x7大小的图片。有时候将7x7的图片做最大池化或平均池化,最终得到一个值,可理解成从该通道提取的一个特征值。到这一步,特征已经和像素位置无关了。
如果希望提取到的特征不是2048维,则可以在后面再加一个输入为2048,输出为目标维度的全连接层。从上述分析中可以大概了解模型的规模,以及运算量。
另外一个常见的问题是:图像处理对图像的大小有没有要求?是不是所有大小的图片都可以直接代入模型?上例中使用224x224大小的图片,经过多层池化,最终变成了7x7大小。当然也可以代入更大图片(图片越大占用资源越多),比如448x224的图片,最终输出为14x7。一般在训练时,往往经过crop裁剪和resize缩放的步骤,把图片变为统一大小。输入模型时往往以batch为单位,同一batch中的数据大小必须一致,否则只能单张处理。
下例为从指定的层提取ResNet50的特征。
import torch
from torch import nn
import torchvision.models as models
import torchvision.transforms as transforms
import cv2
class FeatureExtractor(nn.Module): # 提取特征工具
def __init__(self, submodule, extracted_layers):
super(FeatureExtractor, self).__init__()
self.submodule = submodule
self.extracted_layers = extracted_layers
def forward(self, x):
outputs = []
for name, module in self.submodule._modules.items():
if name is "fc":
x = x.view(x.size(0), -1)
x = module(x)
if name in self.extracted_layers:
outputs.append(x)
return outputs
model = models.resnet50(pretrained=True) # 加载resnet50工具
model = model.cuda()
model.eval()
img=cv2.imread('test.jpg') # 加载图片
img=cv2.resize(img,(224,224));
img=cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
img=transform(img).cuda()
img=img.unsqueeze(0)
model2 = FeatureExtractor(model, ['layer3']) # 指定提取 layer3 层特征
with torch.no_grad():
out=model2(img)
print(len(out), out[0].shape)
使用resnet
import torch
import torch.nn as nn
from torch.autograd import Variable
from torchvision import models, transforms
from PIL import Image
import numpy as np
import os, glob
data_dir = './test' # train
features_dir = './Resnet_features_test' # Resnet_features_train
//这里自己修改网络
class net(nn.Module):
def __init__(self):
super(net, self).__init__()
self.net = models.resnet50(pretrained=True)
def forward(self, input):
output = self.net.conv1(input)
output = self.net.bn1(output)
output = self.net.relu(output)
output = self.net.maxpool(output)
output = self.net.layer1(output)
output = self.net.layer2(output)
output = self.net.layer3(output)
output = self.net.layer4(output)
output = self.net.avgpool(output)
return output
model = net()
//加载cuda
model = model.cuda()
def extractor(img_path, saved_path, net, use_gpu):
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor()]
)
img = Image.open(img_path)
img = transform(img)
print(img.shape)
x = Variable(torch.unsqueeze(img, dim=0).float(), requires_grad=False)
print(x.shape)
if use_gpu:
x = x.cuda()
net = net.cuda()
y = net(x).cpu()
y = torch.squeeze(y)
y = y.data.numpy()
print(y.shape)
np.savetxt(saved_path, y, delimiter=',')
if __name__ == '__main__':
extensions = ['jpg', 'jpeg', 'JPG', 'JPEG']
files_list = []
x = os.walk(data_dir)
for path,d,filelist in x:
for filename in filelist:
file_glob = os.path.join(path, filename)
files_list.extend(glob.glob(file_glob))
print(files_list)
use_gpu = torch.cuda.is_available()
for x_path in files_list:
print("x_path" + x_path)
file_name = x_path.split('/')[-1]
fx_path = os.path.join(features_dir, file_name + '.txt')
print(fx_path)
extractor(x_path, fx_path, model, use_gpu)
使用vgg
import torch
import torch.nn as nn
from torch.autograd import Variable
from torchvision import models, transforms
from PIL import Image
import numpy as np
import os, glob
data_dir = './test' # train
features_dir = './Vgg_features_test' # Vgg_features_train
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
VGG = models.vgg16(pretrained=True)
self.feature = VGG.features
self.classifier = nn.Sequential(*list(VGG.classifier.children())[:-3])
pretrained_dict = VGG.state_dict()
model_dict = self.classifier.state_dict()
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
model_dict.update(pretrained_dict)
self.classifier.load_state_dict(model_dict)
def forward(self, x):
output = self.feature(x)
output = output.view(output.size(0), -1)
output = self.classifier(output)
return output
model = Encoder()
model = model.cuda()
def extractor(img_path, saved_path, net, use_gpu):
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor()]
)
img = Image.open(img_path)
img = transform(img)
print(img.shape)
x = Variable(torch.unsqueeze(img, dim=0).float(), requires_grad=False)
print(x.shape)
if use_gpu:
x = x.cuda()
net = net.cuda()
y = net(x).cpu()
y = torch.squeeze(y)
y = y.data.numpy()
print(y.shape)
np.savetxt(saved_path, y, delimiter=',')
if __name__ == '__main__':
extensions = ['jpg', 'jpeg', 'JPG', 'JPEG']
files_list = []
x = os.walk(data_dir)
for path, d, filelist in x:
for filename in filelist:
file_glob = os.path.join(path, filename)
files_list.extend(glob.glob(file_glob))
print(files_list)
use_gpu = torch.cuda.is_available()
for x_path in files_list:
print("x_path" + x_path)
file_name = x_path.split('/')[-1]
fx_path = os.path.join(features_dir, file_name + '.txt')
print(fx_path)
extractor(x_path, fx_path, model, use_gpu)
使用三个模型的特征提取的方法